2019-10-26 18:12:58 +02:00
|
|
|
//! Low-level Rust lexer.
|
|
|
|
|
//!
|
2020-04-25 20:19:54 +02:00
|
|
|
//! The idea with `librustc_lexer` is to make a reusable library,
|
|
|
|
|
//! by separating out pure lexing and rustc-specific concerns, like spans,
|
|
|
|
|
//! error reporting an interning. So, rustc_lexer operates directly on `&str`,
|
|
|
|
|
//! produces simple tokens which are a pair of type-tag and a bit of original text,
|
|
|
|
|
//! and does not report errors, instead storing them as flags on the token.
|
|
|
|
|
//!
|
2020-06-29 01:32:28 +02:00
|
|
|
//! Tokens produced by this lexer are not yet ready for parsing the Rust syntax.
|
|
|
|
|
//! For that see [`librustc_parse::lexer`], which converts this basic token stream
|
2019-10-26 18:12:58 +02:00
|
|
|
//! into wide tokens used by actual parser.
|
|
|
|
|
//!
|
|
|
|
|
//! The purpose of this crate is to convert raw sources into a labeled sequence
|
|
|
|
|
//! of well-known token types, so building an actual Rust token stream will
|
|
|
|
|
//! be easier.
|
|
|
|
|
//!
|
2020-06-29 01:32:28 +02:00
|
|
|
//! The main entity of this crate is the [`TokenKind`] enum which represents common
|
2019-10-26 18:12:58 +02:00
|
|
|
//! lexeme types.
|
2020-06-29 01:32:28 +02:00
|
|
|
//!
|
|
|
|
|
//! [`librustc_parse::lexer`]: ../rustc_parse/lexer/index.html
|
2019-07-21 13:50:39 +02:00
|
|
|
// We want to be able to build this crate with a stable compiler, so no
|
|
|
|
|
// `#![feature]` attributes should be added.
|
2019-05-06 10:53:40 +02:00
|
|
|
|
|
|
|
|
mod cursor;
|
2019-07-21 15:46:11 +02:00
|
|
|
pub mod unescape;
|
2019-05-06 10:53:40 +02:00
|
|
|
|
2020-03-28 06:46:20 +01:00
|
|
|
#[cfg(test)]
|
|
|
|
|
mod tests;
|
|
|
|
|
|
2019-11-03 10:57:12 +01:00
|
|
|
use self::LiteralKind::*;
|
2019-12-22 23:42:04 +01:00
|
|
|
use self::TokenKind::*;
|
|
|
|
|
use crate::cursor::{Cursor, EOF_CHAR};
|
2020-05-29 17:37:16 +02:00
|
|
|
use std::convert::TryFrom;
|
2019-05-06 10:53:40 +02:00
|
|
|
|
2019-10-26 18:12:58 +02:00
|
|
|
/// Parsed token.
|
|
|
|
|
/// It doesn't contain information about data that has been parsed,
|
|
|
|
|
/// only the type of the token and its size.
|

Introduce expect snapshot testing library into rustc
Snapshot testing is a technique for writing maintainable unit tests.
Unlike usual `assert_eq!` tests, snapshot tests allow
to *automatically* upgrade expected values on test failure.
In a sense, snapshot tests are inline-version of our beloved
UI-tests.
Example:
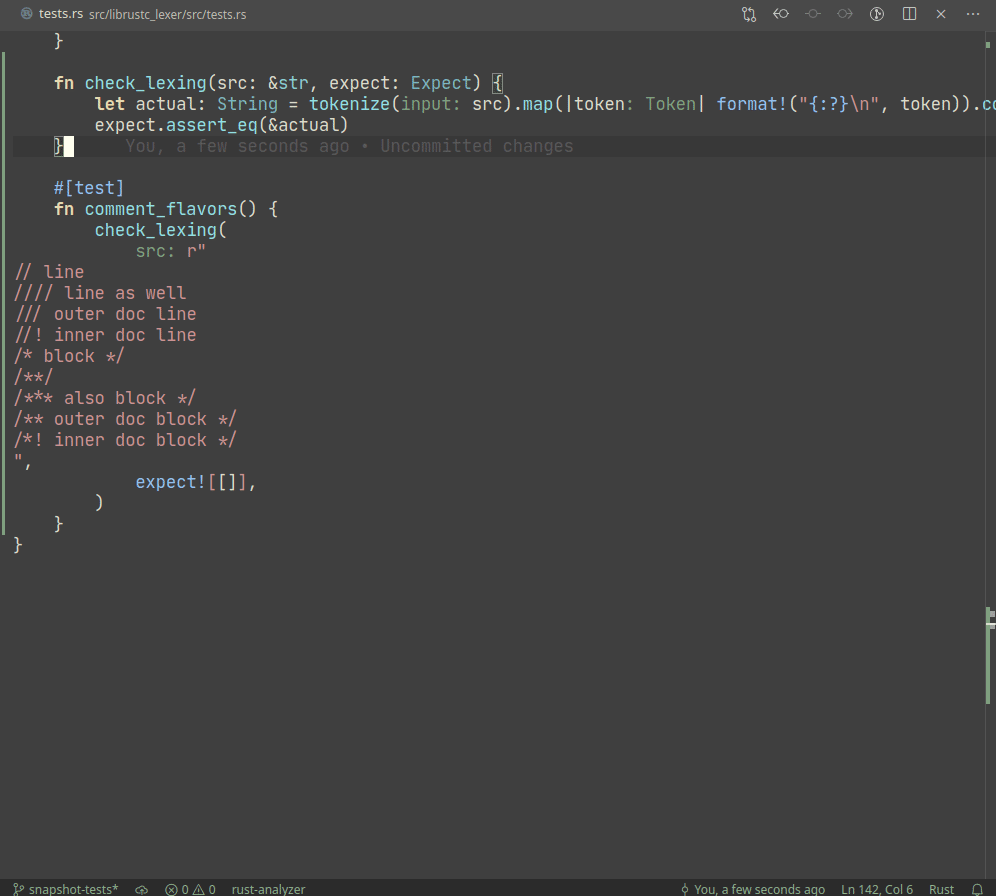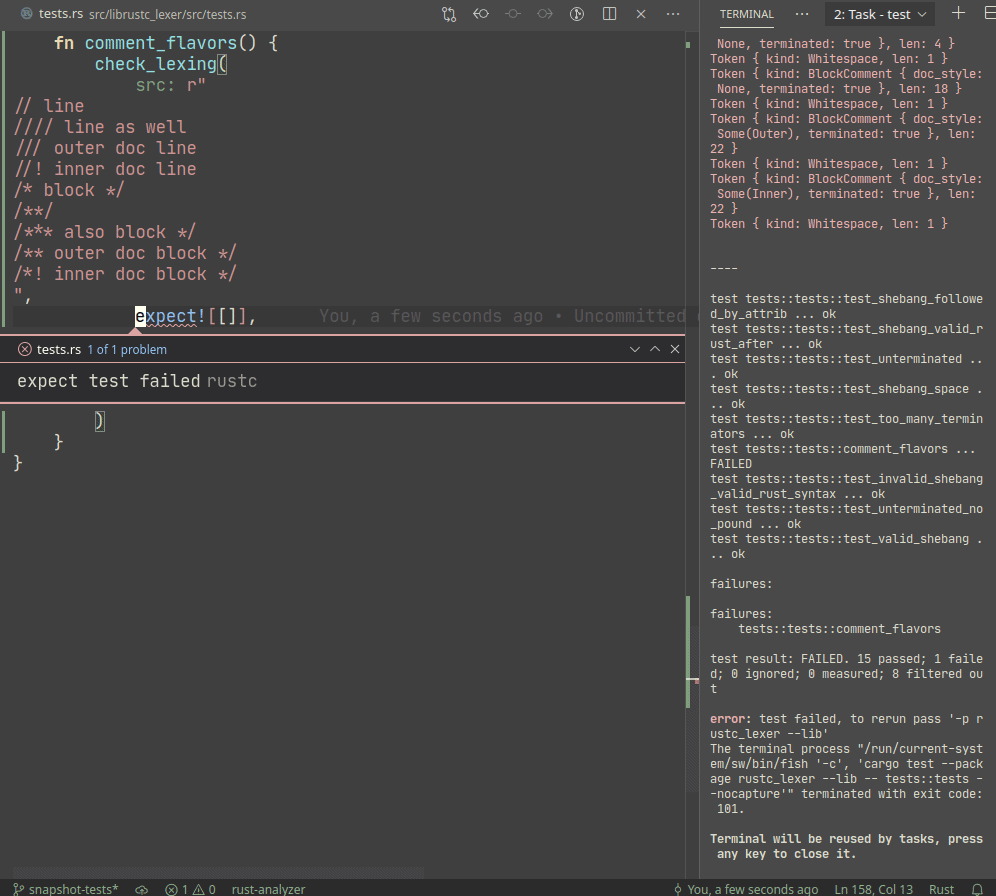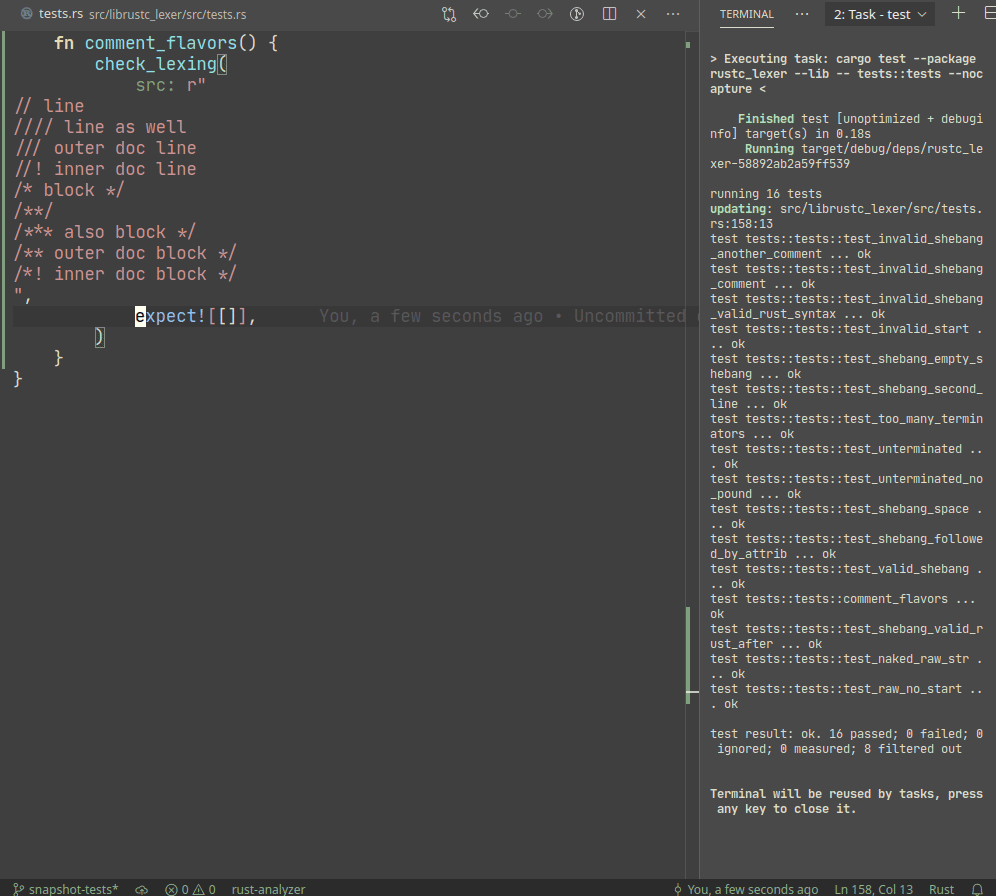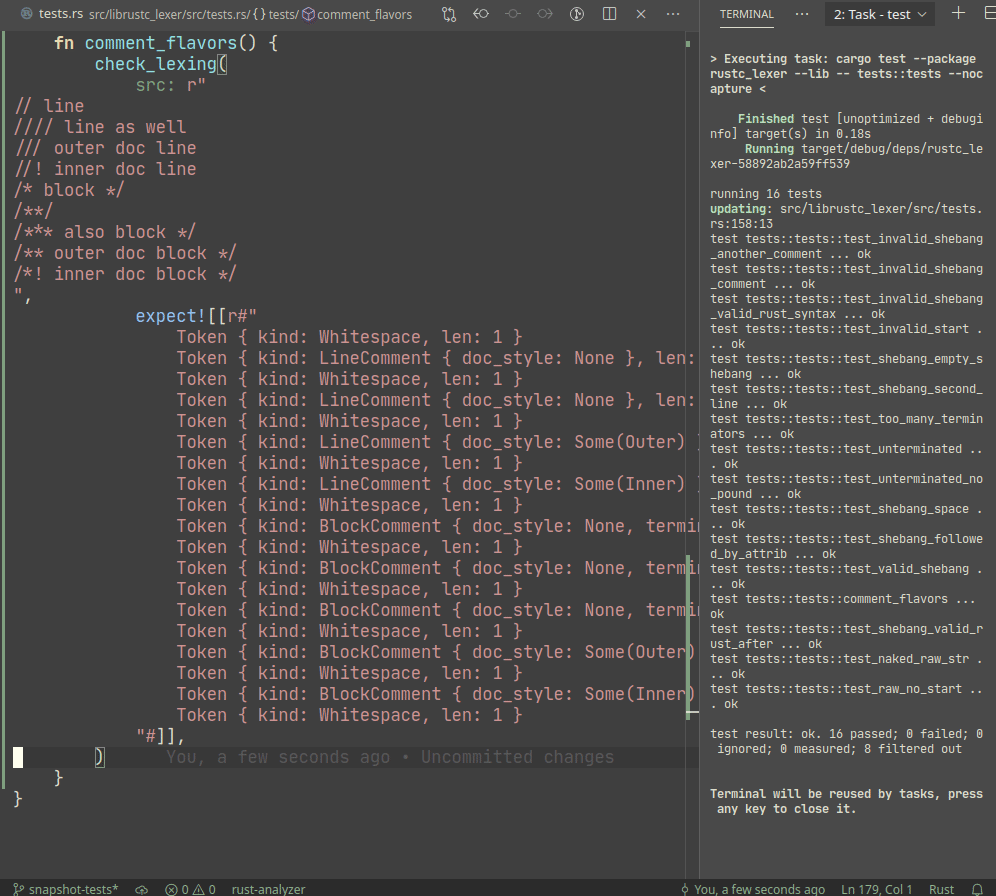
A particular library we use, `expect_test` provides an `expect!`
macro, which creates a sort of self-updating string literal (by using
`file!` macro). Self-update is triggered by setting `UPDATE_EXPECT`
environmental variable (this info is printed during the test failure).
This library was extracted from rust-analyzer, where we use it for
most of our tests.
There are some other, more popular snapshot testing libraries:
* https://github.com/mitsuhiko/insta
* https://github.com/aaronabramov/k9
The main differences of `expect` are:
* first-class snapshot objects (so, tests can be written as functions,
rather than as macros)
* focus on inline-snapshots (but file snapshots are also supported)
* restricted feature set (only `assert_eq` and `assert_debug_eq`)
* no extra runtime (ie, no `cargo insta`)
See https://github.com/rust-analyzer/rust-analyzer/pull/5101 for a
an extended comparison.
It is unclear if this testing style will stick with rustc in the long
run. At the moment, rustc is mainly tested via integrated UI tests.
But in the library-ified world, unit-tests will become somewhat more
important (that's why use use `rustc_lexer` library-ified library as
an example in this PR). Given that the cost of removal shouldn't be
too high, it probably makes sense to just see if this flies!
2020-08-21 14:03:50 +02:00
|
|
|
#[derive(Debug)]
|
2019-05-06 10:53:40 +02:00
|
|
|
pub struct Token {
|
|
|
|
|
pub kind: TokenKind,
|
|
|
|
|
pub len: usize,
|
|
|
|
|
}
|
|
|
|
|
|
2019-10-26 18:12:58 +02:00
|
|
|
impl Token {
|
|
|
|
|
fn new(kind: TokenKind, len: usize) -> Token {
|
|
|
|
|
Token { kind, len }
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
|
2020-02-13 17:14:21 +01:00
|
|
|
/// Enum representing common lexeme types.
|
2019-05-06 10:53:40 +02:00
|
|
|
#[derive(Clone, Copy, Debug, PartialEq, Eq, PartialOrd, Ord)]
|
|
|
|
|
pub enum TokenKind {
|
2019-10-26 18:12:58 +02:00
|
|
|
// Multi-char tokens:
|
|
|
|
|
/// "// comment"
|
2020-08-17 18:43:35 +02:00
|
|
|
LineComment { doc_style: Option<DocStyle> },
|
2020-06-28 22:19:59 +02:00
|
|
|
/// `/* block comment */`
|
|
|
|
|
///
|
|
|
|
|
/// Block comments can be recursive, so the sequence like `/* /* */`
|
2019-10-26 18:12:58 +02:00
|
|
|
/// will not be considered terminated and will result in a parsing error.
|
2020-08-17 18:43:35 +02:00
|
|
|
BlockComment { doc_style: Option<DocStyle>, terminated: bool },
|
2019-10-26 18:12:58 +02:00
|
|
|
/// Any whitespace characters sequence.
|
2019-05-06 10:53:40 +02:00
|
|
|
Whitespace,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "ident" or "continue"
|
|
|
|
|
/// At this step keywords are also considered identifiers.
|
2019-05-06 10:53:40 +02:00
|
|
|
Ident,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "r#ident"
|
2019-05-06 10:53:40 +02:00
|
|
|
RawIdent,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "12_u8", "1.0e-40", "b"123"". See `LiteralKind` for more details.
|
2019-05-06 10:53:40 +02:00
|
|
|
Literal { kind: LiteralKind, suffix_start: usize },
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "'a"
|
2019-05-06 10:53:40 +02:00
|
|
|
Lifetime { starts_with_number: bool },
|
2019-10-26 18:12:58 +02:00
|
|
|
|
|
|
|
|
// One-char tokens:
|
|
|
|
|
/// ";"
|
2019-05-06 10:53:40 +02:00
|
|
|
Semi,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// ","
|
2019-05-06 10:53:40 +02:00
|
|
|
Comma,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "."
|
2019-05-06 10:53:40 +02:00
|
|
|
Dot,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "("
|
2019-05-06 10:53:40 +02:00
|
|
|
OpenParen,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// ")"
|
2019-05-06 10:53:40 +02:00
|
|
|
CloseParen,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "{"
|
2019-05-06 10:53:40 +02:00
|
|
|
OpenBrace,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "}"
|
2019-05-06 10:53:40 +02:00
|
|
|
CloseBrace,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "["
|
2019-05-06 10:53:40 +02:00
|
|
|
OpenBracket,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "]"
|
2019-05-06 10:53:40 +02:00
|
|
|
CloseBracket,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "@"
|
2019-05-06 10:53:40 +02:00
|
|
|
At,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "#"
|
2019-05-06 10:53:40 +02:00
|
|
|
Pound,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "~"
|
2019-05-06 10:53:40 +02:00
|
|
|
Tilde,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "?"
|
2019-05-06 10:53:40 +02:00
|
|
|
Question,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// ":"
|
2019-05-06 10:53:40 +02:00
|
|
|
Colon,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "$"
|
2019-05-06 10:53:40 +02:00
|
|
|
Dollar,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "="
|
2019-05-06 10:53:40 +02:00
|
|
|
Eq,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "!"
|
2020-08-20 15:51:39 +02:00
|
|
|
Bang,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "<"
|
2019-05-06 10:53:40 +02:00
|
|
|
Lt,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// ">"
|
2019-05-06 10:53:40 +02:00
|
|
|
Gt,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "-"
|
2019-05-06 10:53:40 +02:00
|
|
|
Minus,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "&"
|
2019-05-06 10:53:40 +02:00
|
|
|
And,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "|"
|
2019-05-06 10:53:40 +02:00
|
|
|
Or,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "+"
|
2019-05-06 10:53:40 +02:00
|
|
|
Plus,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "*"
|
2019-05-06 10:53:40 +02:00
|
|
|
Star,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "/"
|
2019-05-06 10:53:40 +02:00
|
|
|
Slash,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "^"
|
2019-05-06 10:53:40 +02:00
|
|
|
Caret,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "%"
|
2019-05-06 10:53:40 +02:00
|
|
|
Percent,
|
2019-10-26 18:12:58 +02:00
|
|
|
|
|
|
|
|
/// Unknown token, not expected by the lexer, e.g. "№"
|
2019-05-06 10:53:40 +02:00
|
|
|
Unknown,
|
|
|
|
|
}
|
|
|
|
|
|
2020-08-17 18:43:35 +02:00
|
|
|
#[derive(Clone, Copy, Debug, PartialEq, Eq, PartialOrd, Ord)]
|
|
|
|
|
pub enum DocStyle {
|
|
|
|
|
Outer,
|
|
|
|
|
Inner,
|
|
|
|
|
}
|
|
|
|
|
|
2019-05-06 10:53:40 +02:00
|
|
|
#[derive(Clone, Copy, Debug, PartialEq, Eq, PartialOrd, Ord)]
|
|
|
|
|
pub enum LiteralKind {
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "12_u8", "0o100", "0b120i99"
|
2019-05-06 10:53:40 +02:00
|
|
|
Int { base: Base, empty_int: bool },
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "12.34f32", "0b100.100"
|
2019-05-06 10:53:40 +02:00
|
|
|
Float { base: Base, empty_exponent: bool },
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "'a'", "'\\'", "'''", "';"
|
2019-05-06 10:53:40 +02:00
|
|
|
Char { terminated: bool },
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "b'a'", "b'\\'", "b'''", "b';"
|
2019-05-06 10:53:40 +02:00
|
|
|
Byte { terminated: bool },
|
2019-10-26 18:12:58 +02:00
|
|
|
/// ""abc"", ""abc"
|
2019-05-06 10:53:40 +02:00
|
|
|
Str { terminated: bool },
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "b"abc"", "b"abc"
|
2019-05-06 10:53:40 +02:00
|
|
|
ByteStr { terminated: bool },
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "r"abc"", "r#"abc"#", "r####"ab"###"c"####", "r#"a"
|
2020-05-29 17:37:16 +02:00
|
|
|
RawStr { n_hashes: u16, err: Option<RawStrError> },
|
2019-10-26 18:12:58 +02:00
|
|
|
/// "br"abc"", "br#"abc"#", "br####"ab"###"c"####", "br#"a"
|
2020-05-29 17:37:16 +02:00
|
|
|
RawByteStr { n_hashes: u16, err: Option<RawStrError> },
|
2020-03-28 06:46:20 +01:00
|
|
|
}
|
|
|
|
|
|
2020-03-29 17:12:48 +02:00
|
|
|
/// Error produced validating a raw string. Represents cases like:
|
2020-05-29 17:37:16 +02:00
|
|
|
/// - `r##~"abcde"##`: `InvalidStarter`
|
|
|
|
|
/// - `r###"abcde"##`: `NoTerminator { expected: 3, found: 2, possible_terminator_offset: Some(11)`
|
|
|
|
|
/// - Too many `#`s (>65535): `TooManyDelimiters`
|
2020-03-28 06:46:20 +01:00
|
|
|
#[derive(Clone, Copy, Debug, PartialEq, Eq, PartialOrd, Ord)]
|
2020-05-29 17:37:16 +02:00
|
|
|
pub enum RawStrError {
|
2020-03-29 17:12:48 +02:00
|
|
|
/// Non `#` characters exist between `r` and `"` eg. `r#~"..`
|
2020-05-29 17:37:16 +02:00
|
|
|
InvalidStarter { bad_char: char },
|
2020-03-29 17:12:48 +02:00
|
|
|
/// The string was never terminated. `possible_terminator_offset` is the number of characters after `r` or `br` where they
|
2020-03-28 06:46:20 +01:00
|
|
|
/// may have intended to terminate it.
|
|
|
|
|
NoTerminator { expected: usize, found: usize, possible_terminator_offset: Option<usize> },
|
2020-05-29 17:37:16 +02:00
|
|
|
/// More than 65535 `#`s exist.
|
|
|
|
|
TooManyDelimiters { found: usize },
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
|
|
|
|
|
2019-10-26 18:12:58 +02:00
|
|
|
/// Base of numeric literal encoding according to its prefix.
|
2019-05-06 10:53:40 +02:00
|
|
|
#[derive(Clone, Copy, Debug, PartialEq, Eq, PartialOrd, Ord)]
|
|
|
|
|
pub enum Base {
|
2019-10-26 18:12:58 +02:00
|
|
|
/// Literal starts with "0b".
|
2019-05-06 10:53:40 +02:00
|
|
|
Binary,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// Literal starts with "0o".
|
2019-05-06 10:53:40 +02:00
|
|
|
Octal,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// Literal starts with "0x".
|
2019-05-06 10:53:40 +02:00
|
|
|
Hexadecimal,
|
2019-10-26 18:12:58 +02:00
|
|
|
/// Literal doesn't contain a prefix.
|
2019-05-06 10:53:40 +02:00
|
|
|
Decimal,
|
|
|
|
|
}
|
|
|
|
|
|
2019-10-26 18:12:58 +02:00
|
|
|
/// `rustc` allows files to have a shebang, e.g. "#!/usr/bin/rustrun",
|
Fix bug in shebang handling
Shebang handling was too agressive in stripping out the first line in cases where it is actually _not_ a shebang, but instead, valid rust (#70528). This is a second attempt at resolving this issue (the first attempt was flawed, for, among other reasons, causing an ICE in certain cases (#71372, #71471).
The behavior is now codified by a number of UI tests, but simply:
For the first line to be a shebang, the following must all be true:
1. The line must start with `#!`
2. The line must contain a non whitespace character after `#!`
3. The next character in the file, ignoring comments & whitespace must not be `[`
I believe this is a strict superset of what we used to allow, so perhaps a crater run is unnecessary, but probably not a terrible idea.
2020-04-23 21:51:12 +02:00
|
|
|
/// but shebang isn't a part of rust syntax.
|
2019-05-06 10:53:40 +02:00
|
|
|
pub fn strip_shebang(input: &str) -> Option<usize> {
|
2020-05-29 20:51:46 +02:00
|
|
|
// Shebang must start with `#!` literally, without any preceding whitespace.
|
2020-06-21 23:40:11 +02:00
|
|
|
// For simplicity we consider any line starting with `#!` a shebang,
|
|
|
|
|
// regardless of restrictions put on shebangs by specific platforms.
|
|
|
|
|
if let Some(input_tail) = input.strip_prefix("#!") {
|
|
|
|
|
// Ok, this is a shebang but if the next non-whitespace token is `[` or maybe
|
|
|
|
|
// a doc comment (due to `TokenKind::(Line,Block)Comment` ambiguity at lexer level),
|
|
|
|
|
// then it may be valid Rust code, so consider it Rust code.
|
|
|
|
|
let next_non_whitespace_token = tokenize(input_tail).map(|tok| tok.kind).find(|tok|
|
2020-08-17 18:43:35 +02:00
|
|
|
!matches!(tok, TokenKind::Whitespace | TokenKind::LineComment { .. } | TokenKind::BlockComment { .. })
|
2020-06-21 23:40:11 +02:00
|
|
|
);
|
|
|
|
|
if next_non_whitespace_token != Some(TokenKind::OpenBracket) {
|
|
|
|
|
// No other choice than to consider this a shebang.
|
|
|
|
|
return Some(2 + input_tail.lines().next().unwrap_or_default().len());
|
2020-05-29 20:51:46 +02:00
|
|
|
}
|
Fix bug in shebang handling
Shebang handling was too agressive in stripping out the first line in cases where it is actually _not_ a shebang, but instead, valid rust (#70528). This is a second attempt at resolving this issue (the first attempt was flawed, for, among other reasons, causing an ICE in certain cases (#71372, #71471).
The behavior is now codified by a number of UI tests, but simply:
For the first line to be a shebang, the following must all be true:
1. The line must start with `#!`
2. The line must contain a non whitespace character after `#!`
3. The next character in the file, ignoring comments & whitespace must not be `[`
I believe this is a strict superset of what we used to allow, so perhaps a crater run is unnecessary, but probably not a terrible idea.
2020-04-23 21:51:12 +02:00
|
|
|
}
|
2020-05-29 20:51:46 +02:00
|
|
|
None
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
|
|
|
|
|
2019-10-26 18:12:58 +02:00
|
|
|
/// Parses the first token from the provided input string.
|
2019-05-06 10:53:40 +02:00
|
|
|
pub fn first_token(input: &str) -> Token {
|
|
|
|
|
debug_assert!(!input.is_empty());
|
|
|
|
|
Cursor::new(input).advance_token()
|
|
|
|
|
}
|
|
|
|
|
|
2019-10-26 18:12:58 +02:00
|
|
|
/// Creates an iterator that produces tokens from the input string.
|
2019-05-06 10:53:40 +02:00
|
|
|
pub fn tokenize(mut input: &str) -> impl Iterator<Item = Token> + '_ {
|
|
|
|
|
std::iter::from_fn(move || {
|
|
|
|
|
if input.is_empty() {
|
|
|
|
|
return None;
|
|
|
|
|
}
|
|
|
|
|
let token = first_token(input);
|
|
|
|
|
input = &input[token.len..];
|
|
|
|
|
Some(token)
|
|
|
|
|
})
|
|
|
|
|
}
|
|
|
|
|
|
2019-09-04 12:16:36 +02:00
|
|
|
/// True if `c` is considered a whitespace according to Rust language definition.
|
2019-10-26 18:12:58 +02:00
|
|
|
/// See [Rust language reference](https://doc.rust-lang.org/reference/whitespace.html)
|
|
|
|
|
/// for definitions of these classes.
|
2019-09-04 12:16:36 +02:00
|
|
|
pub fn is_whitespace(c: char) -> bool {
|
|
|
|
|
// This is Pattern_White_Space.
|
|
|
|
|
//
|
|
|
|
|
// Note that this set is stable (ie, it doesn't change with different
|
|
|
|
|
// Unicode versions), so it's ok to just hard-code the values.
|
|
|
|
|
|
|
|
|
|
match c {
|
|
|
|
|
// Usual ASCII suspects
|
|
|
|
|
| '\u{0009}' // \t
|
|
|
|
|
| '\u{000A}' // \n
|
|
|
|
|
| '\u{000B}' // vertical tab
|
|
|
|
|
| '\u{000C}' // form feed
|
|
|
|
|
| '\u{000D}' // \r
|
|
|
|
|
| '\u{0020}' // space
|
|
|
|
|
|
|
|
|
|
// NEXT LINE from latin1
|
|
|
|
|
| '\u{0085}'
|
|
|
|
|
|
|
|
|
|
// Bidi markers
|
|
|
|
|
| '\u{200E}' // LEFT-TO-RIGHT MARK
|
|
|
|
|
| '\u{200F}' // RIGHT-TO-LEFT MARK
|
|
|
|
|
|
|
|
|
|
// Dedicated whitespace characters from Unicode
|
|
|
|
|
| '\u{2028}' // LINE SEPARATOR
|
|
|
|
|
| '\u{2029}' // PARAGRAPH SEPARATOR
|
2020-03-28 06:46:20 +01:00
|
|
|
=> true,
|
2019-09-04 12:16:36 +02:00
|
|
|
_ => false,
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
/// True if `c` is valid as a first character of an identifier.
|
2019-10-26 18:12:58 +02:00
|
|
|
/// See [Rust language reference](https://doc.rust-lang.org/reference/identifiers.html) for
|
|
|
|
|
/// a formal definition of valid identifier name.
|
2019-09-04 12:16:36 +02:00
|
|
|
pub fn is_id_start(c: char) -> bool {
|
|
|
|
|
// This is XID_Start OR '_' (which formally is not a XID_Start).
|
|
|
|
|
// We also add fast-path for ascii idents
|
|
|
|
|
('a' <= c && c <= 'z')
|
|
|
|
|
|| ('A' <= c && c <= 'Z')
|
|
|
|
|
|| c == '_'
|
|
|
|
|
|| (c > '\x7f' && unicode_xid::UnicodeXID::is_xid_start(c))
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
/// True if `c` is valid as a non-first character of an identifier.
|
2019-10-26 18:12:58 +02:00
|
|
|
/// See [Rust language reference](https://doc.rust-lang.org/reference/identifiers.html) for
|
|
|
|
|
/// a formal definition of valid identifier name.
|
2019-09-04 12:16:36 +02:00
|
|
|
pub fn is_id_continue(c: char) -> bool {
|
|
|
|
|
// This is exactly XID_Continue.
|
|
|
|
|
// We also add fast-path for ascii idents
|
|
|
|
|
('a' <= c && c <= 'z')
|
|
|
|
|
|| ('A' <= c && c <= 'Z')
|
|
|
|
|
|| ('0' <= c && c <= '9')
|
|
|
|
|
|| c == '_'
|
|
|
|
|
|| (c > '\x7f' && unicode_xid::UnicodeXID::is_xid_continue(c))
|
|
|
|
|
}
|
|
|
|
|
|
2020-08-10 21:27:48 +02:00
|
|
|
/// The passed string is lexically an identifier.
|
|
|
|
|
pub fn is_ident(string: &str) -> bool {
|
|
|
|
|
let mut chars = string.chars();
|
|
|
|
|
if let Some(start) = chars.next() {
|
|
|
|
|
is_id_start(start) && chars.all(is_id_continue)
|
|
|
|
|
} else {
|
|
|
|
|
false
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
|
2019-05-06 10:53:40 +02:00
|
|
|
impl Cursor<'_> {
|
2019-10-26 18:12:58 +02:00
|
|
|
/// Parses a token from the input string.
|
2019-05-06 10:53:40 +02:00
|
|
|
fn advance_token(&mut self) -> Token {
|
|
|
|
|
let first_char = self.bump().unwrap();
|
|
|
|
|
let token_kind = match first_char {
|
2019-10-26 18:12:58 +02:00
|
|
|
// Slash, comment or block comment.
|
2019-11-03 09:39:39 +01:00
|
|
|
'/' => match self.first() {
|
2019-05-06 10:53:40 +02:00
|
|
|
'/' => self.line_comment(),
|
|
|
|
|
'*' => self.block_comment(),
|
2019-08-19 18:00:24 +02:00
|
|
|
_ => Slash,
|
2019-05-06 10:53:40 +02:00
|
|
|
},
|
2019-10-26 18:12:58 +02:00
|
|
|
|
|
|
|
|
// Whitespace sequence.
|
2019-09-04 12:16:36 +02:00
|
|
|
c if is_whitespace(c) => self.whitespace(),
|
2019-10-26 18:12:58 +02:00
|
|
|
|
2019-11-03 09:39:39 +01:00
|
|
|
// Raw identifier, raw string literal or identifier.
|
|
|
|
|
'r' => match (self.first(), self.second()) {
|
2019-09-04 12:16:36 +02:00
|
|
|
('#', c1) if is_id_start(c1) => self.raw_ident(),
|
2019-05-06 10:53:40 +02:00
|
|
|
('#', _) | ('"', _) => {
|
2020-05-29 17:37:16 +02:00
|
|
|
let (n_hashes, err) = self.raw_double_quoted_string(1);
|
2019-05-06 10:53:40 +02:00
|
|
|
let suffix_start = self.len_consumed();
|
2020-05-29 17:37:16 +02:00
|
|
|
if err.is_none() {
|
2019-05-06 10:53:40 +02:00
|
|
|
self.eat_literal_suffix();
|
|
|
|
|
}
|
2020-05-29 17:37:16 +02:00
|
|
|
let kind = RawStr { n_hashes, err };
|
2019-05-06 10:53:40 +02:00
|
|
|
Literal { kind, suffix_start }
|
|
|
|
|
}
|
|
|
|
|
_ => self.ident(),
|
|
|
|
|
},
|
2019-10-26 18:12:58 +02:00
|
|
|
|
|
|
|
|
// Byte literal, byte string literal, raw byte string literal or identifier.
|
2019-11-03 09:39:39 +01:00
|
|
|
'b' => match (self.first(), self.second()) {
|
2019-05-06 10:53:40 +02:00
|
|
|
('\'', _) => {
|
|
|
|
|
self.bump();
|
|
|
|
|
let terminated = self.single_quoted_string();
|
|
|
|
|
let suffix_start = self.len_consumed();
|
|
|
|
|
if terminated {
|
|
|
|
|
self.eat_literal_suffix();
|
|
|
|
|
}
|
|
|
|
|
let kind = Byte { terminated };
|
|
|
|
|
Literal { kind, suffix_start }
|
|
|
|
|
}
|
|
|
|
|
('"', _) => {
|
|
|
|
|
self.bump();
|
|
|
|
|
let terminated = self.double_quoted_string();
|
|
|
|
|
let suffix_start = self.len_consumed();
|
|
|
|
|
if terminated {
|
|
|
|
|
self.eat_literal_suffix();
|
|
|
|
|
}
|
|
|
|
|
let kind = ByteStr { terminated };
|
|
|
|
|
Literal { kind, suffix_start }
|
|
|
|
|
}
|
|
|
|
|
('r', '"') | ('r', '#') => {
|
|
|
|
|
self.bump();
|
2020-05-29 17:37:16 +02:00
|
|
|
let (n_hashes, err) = self.raw_double_quoted_string(2);
|
2019-05-06 10:53:40 +02:00
|
|
|
let suffix_start = self.len_consumed();
|
2020-05-29 17:37:16 +02:00
|
|
|
if err.is_none() {
|
2019-05-06 10:53:40 +02:00
|
|
|
self.eat_literal_suffix();
|
|
|
|
|
}
|
2020-05-29 17:37:16 +02:00
|
|
|
let kind = RawByteStr { n_hashes, err };
|
2019-05-06 10:53:40 +02:00
|
|
|
Literal { kind, suffix_start }
|
|
|
|
|
}
|
|
|
|
|
_ => self.ident(),
|
|
|
|
|
},
|
2019-10-26 18:12:58 +02:00
|
|
|
|
|
|
|
|
// Identifier (this should be checked after other variant that can
|
|
|
|
|
// start as identifier).
|
2019-09-04 12:16:36 +02:00
|
|
|
c if is_id_start(c) => self.ident(),
|
2019-10-26 18:12:58 +02:00
|
|
|
|
|
|
|
|
// Numeric literal.
|
2019-05-06 10:53:40 +02:00
|
|
|
c @ '0'..='9' => {
|
|
|
|
|
let literal_kind = self.number(c);
|
|
|
|
|
let suffix_start = self.len_consumed();
|
|
|
|
|
self.eat_literal_suffix();
|
|
|
|
|
TokenKind::Literal { kind: literal_kind, suffix_start }
|
|
|
|
|
}
|
2019-10-26 18:12:58 +02:00
|
|
|
|
|
|
|
|
// One-symbol tokens.
|
2019-05-06 10:53:40 +02:00
|
|
|
';' => Semi,
|
|
|
|
|
',' => Comma,
|
2019-08-19 18:00:24 +02:00
|
|
|
'.' => Dot,
|
2019-05-06 10:53:40 +02:00
|
|
|
'(' => OpenParen,
|
|
|
|
|
')' => CloseParen,
|
|
|
|
|
'{' => OpenBrace,
|
|
|
|
|
'}' => CloseBrace,
|
|
|
|
|
'[' => OpenBracket,
|
|
|
|
|
']' => CloseBracket,
|
|
|
|
|
'@' => At,
|
|
|
|
|
'#' => Pound,
|
|
|
|
|
'~' => Tilde,
|
|
|
|
|
'?' => Question,
|
2019-08-19 18:00:24 +02:00
|
|
|
':' => Colon,
|
2019-05-06 10:53:40 +02:00
|
|
|
'$' => Dollar,
|
2019-08-19 18:00:24 +02:00
|
|
|
'=' => Eq,
|
2020-08-20 15:51:39 +02:00
|
|
|
'!' => Bang,
|
2019-08-19 18:00:24 +02:00
|
|
|
'<' => Lt,
|
|
|
|
|
'>' => Gt,
|
|
|
|
|
'-' => Minus,
|
|
|
|
|
'&' => And,
|
|
|
|
|
'|' => Or,
|
|
|
|
|
'+' => Plus,
|
|
|
|
|
'*' => Star,
|
|
|
|
|
'^' => Caret,
|
|
|
|
|
'%' => Percent,
|
2019-10-26 18:12:58 +02:00
|
|
|
|
|
|
|
|
// Lifetime or character literal.
|
2019-05-06 10:53:40 +02:00
|
|
|
'\'' => self.lifetime_or_char(),
|
2019-10-26 18:12:58 +02:00
|
|
|
|
|
|
|
|
// String literal.
|
2019-05-06 10:53:40 +02:00
|
|
|
'"' => {
|
|
|
|
|
let terminated = self.double_quoted_string();
|
|
|
|
|
let suffix_start = self.len_consumed();
|
|
|
|
|
if terminated {
|
|
|
|
|
self.eat_literal_suffix();
|
|
|
|
|
}
|
|
|
|
|
let kind = Str { terminated };
|
|
|
|
|
Literal { kind, suffix_start }
|
|
|
|
|
}
|
|
|
|
|
_ => Unknown,
|
|
|
|
|
};
|
|
|
|
|
Token::new(token_kind, self.len_consumed())
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
fn line_comment(&mut self) -> TokenKind {
|
2019-11-03 09:39:39 +01:00
|
|
|
debug_assert!(self.prev() == '/' && self.first() == '/');
|
2019-05-06 10:53:40 +02:00
|
|
|
self.bump();
|
2020-08-17 18:43:35 +02:00
|
|
|
|
|
|
|
|
let doc_style = match self.first() {
|
|
|
|
|
// `//!` is an inner line doc comment.
|
|
|
|
|
'!' => Some(DocStyle::Inner),
|
|
|
|
|
// `////` (more than 3 slashes) is not considered a doc comment.
|
|
|
|
|
'/' if self.second() != '/' => Some(DocStyle::Outer),
|
|
|
|
|
_ => None,
|
|
|
|
|
};
|
|
|
|
|
|
2019-11-03 09:42:08 +01:00
|
|
|
self.eat_while(|c| c != '\n');
|
2020-08-17 18:43:35 +02:00
|
|
|
LineComment { doc_style }
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
|
|
|
|
|
|
|
|
|
fn block_comment(&mut self) -> TokenKind {
|
2019-11-03 09:39:39 +01:00
|
|
|
debug_assert!(self.prev() == '/' && self.first() == '*');
|
2019-05-06 10:53:40 +02:00
|
|
|
self.bump();
|
2020-08-17 18:43:35 +02:00
|
|
|
|
|
|
|
|
let doc_style = match self.first() {
|
|
|
|
|
// `/*!` is an inner block doc comment.
|
|
|
|
|
'!' => Some(DocStyle::Inner),
|
|
|
|
|
// `/***` (more than 2 stars) is not considered a doc comment.
|
|
|
|
|
// `/**/` is not considered a doc comment.
|
|
|
|
|
'*' if !matches!(self.second(), '*' | '/') => Some(DocStyle::Outer),
|
|
|
|
|
_ => None,
|
|
|
|
|
};
|
|
|
|
|
|
2019-05-06 10:53:40 +02:00
|
|
|
let mut depth = 1usize;
|
|
|
|
|
while let Some(c) = self.bump() {
|
|
|
|
|
match c {
|
2019-11-03 09:39:39 +01:00
|
|
|
'/' if self.first() == '*' => {
|
2019-05-06 10:53:40 +02:00
|
|
|
self.bump();
|
|
|
|
|
depth += 1;
|
|
|
|
|
}
|
2019-11-03 09:39:39 +01:00
|
|
|
'*' if self.first() == '/' => {
|
2019-05-06 10:53:40 +02:00
|
|
|
self.bump();
|
|
|
|
|
depth -= 1;
|
|
|
|
|
if depth == 0 {
|
2019-10-26 18:12:58 +02:00
|
|
|
// This block comment is closed, so for a construction like "/* */ */"
|
|
|
|
|
// there will be a successfully parsed block comment "/* */"
|
|
|
|
|
// and " */" will be processed separately.
|
2019-05-06 10:53:40 +02:00
|
|
|
break;
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
_ => (),
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
|
2020-08-17 18:43:35 +02:00
|
|
|
BlockComment { doc_style, terminated: depth == 0 }
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
|
|
|
|
|
|
|
|
|
fn whitespace(&mut self) -> TokenKind {
|
2019-09-04 12:16:36 +02:00
|
|
|
debug_assert!(is_whitespace(self.prev()));
|
2019-11-03 09:42:08 +01:00
|
|
|
self.eat_while(is_whitespace);
|
2019-05-06 10:53:40 +02:00
|
|
|
Whitespace
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
fn raw_ident(&mut self) -> TokenKind {
|
2019-12-22 23:42:04 +01:00
|
|
|
debug_assert!(self.prev() == 'r' && self.first() == '#' && is_id_start(self.second()));
|
2019-11-03 09:42:08 +01:00
|
|
|
// Eat "#" symbol.
|
2019-05-06 10:53:40 +02:00
|
|
|
self.bump();
|
2019-11-03 09:42:08 +01:00
|
|
|
// Eat the identifier part of RawIdent.
|
|
|
|
|
self.eat_identifier();
|
2019-05-06 10:53:40 +02:00
|
|
|
RawIdent
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
fn ident(&mut self) -> TokenKind {
|
2019-09-04 12:16:36 +02:00
|
|
|
debug_assert!(is_id_start(self.prev()));
|
2019-11-03 09:42:08 +01:00
|
|
|
// Start is already eaten, eat the rest of identifier.
|
|
|
|
|
self.eat_while(is_id_continue);
|
2019-05-06 10:53:40 +02:00
|
|
|
Ident
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
fn number(&mut self, first_digit: char) -> LiteralKind {
|
|
|
|
|
debug_assert!('0' <= self.prev() && self.prev() <= '9');
|
|
|
|
|
let mut base = Base::Decimal;
|
|
|
|
|
if first_digit == '0' {
|
2019-10-26 18:12:58 +02:00
|
|
|
// Attempt to parse encoding base.
|
2019-11-03 09:39:39 +01:00
|
|
|
let has_digits = match self.first() {
|
2019-05-06 10:53:40 +02:00
|
|
|
'b' => {
|
|
|
|
|
base = Base::Binary;
|
|
|
|
|
self.bump();
|
|
|
|
|
self.eat_decimal_digits()
|
|
|
|
|
}
|
|
|
|
|
'o' => {
|
|
|
|
|
base = Base::Octal;
|
|
|
|
|
self.bump();
|
|
|
|
|
self.eat_decimal_digits()
|
|
|
|
|
}
|
|
|
|
|
'x' => {
|
|
|
|
|
base = Base::Hexadecimal;
|
|
|
|
|
self.bump();
|
|
|
|
|
self.eat_hexadecimal_digits()
|
|
|
|
|
}
|
2019-10-26 18:12:58 +02:00
|
|
|
// Not a base prefix.
|
2019-05-06 10:53:40 +02:00
|
|
|
'0'..='9' | '_' | '.' | 'e' | 'E' => {
|
|
|
|
|
self.eat_decimal_digits();
|
|
|
|
|
true
|
|
|
|
|
}
|
2019-10-26 18:12:58 +02:00
|
|
|
// Just a 0.
|
2019-05-06 10:53:40 +02:00
|
|
|
_ => return Int { base, empty_int: false },
|
|
|
|
|
};
|
2019-10-26 18:12:58 +02:00
|
|
|
// Base prefix was provided, but there were no digits
|
|
|
|
|
// after it, e.g. "0x".
|
2019-05-06 10:53:40 +02:00
|
|
|
if !has_digits {
|
|
|
|
|
return Int { base, empty_int: true };
|
|
|
|
|
}
|
|
|
|
|
} else {
|
2019-10-26 18:12:58 +02:00
|
|
|
// No base prefix, parse number in the usual way.
|
2019-05-06 10:53:40 +02:00
|
|
|
self.eat_decimal_digits();
|
|
|
|
|
};
|
|
|
|
|
|
2019-11-03 09:39:39 +01:00
|
|
|
match self.first() {
|
2019-05-06 10:53:40 +02:00
|
|
|
// Don't be greedy if this is actually an
|
|
|
|
|
// integer literal followed by field/method access or a range pattern
|
|
|
|
|
// (`0..2` and `12.foo()`)
|
2019-12-22 23:42:04 +01:00
|
|
|
'.' if self.second() != '.' && !is_id_start(self.second()) => {
|
2019-05-06 10:53:40 +02:00
|
|
|
// might have stuff after the ., and if it does, it needs to start
|
|
|
|
|
// with a number
|
|
|
|
|
self.bump();
|
|
|
|
|
let mut empty_exponent = false;
|
2019-11-03 09:39:39 +01:00
|
|
|
if self.first().is_digit(10) {
|
2019-05-06 10:53:40 +02:00
|
|
|
self.eat_decimal_digits();
|
2019-11-03 09:39:39 +01:00
|
|
|
match self.first() {
|
2019-05-06 10:53:40 +02:00
|
|
|
'e' | 'E' => {
|
|
|
|
|
self.bump();
|
2019-11-03 09:43:47 +01:00
|
|
|
empty_exponent = !self.eat_float_exponent();
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
|
|
|
|
_ => (),
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
Float { base, empty_exponent }
|
|
|
|
|
}
|
|
|
|
|
'e' | 'E' => {
|
|
|
|
|
self.bump();
|
2019-11-03 09:43:47 +01:00
|
|
|
let empty_exponent = !self.eat_float_exponent();
|
2019-05-06 10:53:40 +02:00
|
|
|
Float { base, empty_exponent }
|
|
|
|
|
}
|
|
|
|
|
_ => Int { base, empty_int: false },
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
fn lifetime_or_char(&mut self) -> TokenKind {
|
|
|
|
|
debug_assert!(self.prev() == '\'');
|
2019-10-26 18:12:58 +02:00
|
|
|
|
2019-11-03 10:56:49 +01:00
|
|
|
let can_be_a_lifetime = if self.second() == '\'' {
|
|
|
|
|
// It's surely not a lifetime.
|
|
|
|
|
false
|
|
|
|
|
} else {
|
|
|
|
|
// If the first symbol is valid for identifier, it can be a lifetime.
|
|
|
|
|
// Also check if it's a number for a better error reporting (so '0 will
|
|
|
|
|
// be reported as invalid lifetime and not as unterminated char literal).
|
|
|
|
|
is_id_start(self.first()) || self.first().is_digit(10)
|
|
|
|
|
};
|
2019-05-06 10:53:40 +02:00
|
|
|
|
2019-11-03 10:56:49 +01:00
|
|
|
if !can_be_a_lifetime {
|
|
|
|
|
let terminated = self.single_quoted_string();
|
|
|
|
|
let suffix_start = self.len_consumed();
|
|
|
|
|
if terminated {
|
|
|
|
|
self.eat_literal_suffix();
|
|
|
|
|
}
|
|
|
|
|
let kind = Char { terminated };
|
|
|
|
|
return Literal { kind, suffix_start };
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
2019-10-26 18:12:58 +02:00
|
|
|
|
2019-11-03 10:56:49 +01:00
|
|
|
// Either a lifetime or a character literal with
|
|
|
|
|
// length greater than 1.
|
|
|
|
|
|
|
|
|
|
let starts_with_number = self.first().is_digit(10);
|
|
|
|
|
|
|
|
|
|
// Skip the literal contents.
|
|
|
|
|
// First symbol can be a number (which isn't a valid identifier start),
|
|
|
|
|
// so skip it without any checks.
|
|
|
|
|
self.bump();
|
|
|
|
|
self.eat_while(is_id_continue);
|
|
|
|
|
|
|
|
|
|
// Check if after skipping literal contents we've met a closing
|
|
|
|
|
// single quote (which means that user attempted to create a
|
|
|
|
|
// string with single quotes).
|
|
|
|
|
if self.first() == '\'' {
|
|
|
|
|
self.bump();
|
|
|
|
|
let kind = Char { terminated: true };
|
2020-03-20 15:03:11 +01:00
|
|
|
Literal { kind, suffix_start: self.len_consumed() }
|
|
|
|
|
} else {
|
|
|
|
|
Lifetime { starts_with_number }
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
fn single_quoted_string(&mut self) -> bool {
|
|
|
|
|
debug_assert!(self.prev() == '\'');
|
2019-11-03 10:54:23 +01:00
|
|
|
// Check if it's a one-symbol literal.
|
|
|
|
|
if self.second() == '\'' && self.first() != '\\' {
|
2019-05-06 10:53:40 +02:00
|
|
|
self.bump();
|
2019-11-03 10:54:23 +01:00
|
|
|
self.bump();
|
|
|
|
|
return true;
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
2019-11-03 10:54:23 +01:00
|
|
|
|
|
|
|
|
// Literal has more than one symbol.
|
|
|
|
|
|
2019-10-26 18:12:58 +02:00
|
|
|
// Parse until either quotes are terminated or error is detected.
|
2019-05-06 10:53:40 +02:00
|
|
|
loop {
|
2019-11-03 09:39:39 +01:00
|
|
|
match self.first() {
|
2019-10-26 18:12:58 +02:00
|
|
|
// Quotes are terminated, finish parsing.
|
2019-05-06 10:53:40 +02:00
|
|
|
'\'' => {
|
|
|
|
|
self.bump();
|
|
|
|
|
return true;
|
|
|
|
|
}
|
2019-11-03 10:54:23 +01:00
|
|
|
// Probably beginning of the comment, which we don't want to include
|
|
|
|
|
// to the error report.
|
|
|
|
|
'/' => break,
|
|
|
|
|
// Newline without following '\'' means unclosed quote, stop parsing.
|
|
|
|
|
'\n' if self.second() != '\'' => break,
|
|
|
|
|
// End of file, stop parsing.
|
|
|
|
|
EOF_CHAR if self.is_eof() => break,
|
2019-10-26 18:12:58 +02:00
|
|
|
// Escaped slash is considered one character, so bump twice.
|
2019-05-06 10:53:40 +02:00
|
|
|
'\\' => {
|
|
|
|
|
self.bump();
|
|
|
|
|
self.bump();
|
|
|
|
|
}
|
2019-10-26 18:12:58 +02:00
|
|
|
// Skip the character.
|
2019-05-06 10:53:40 +02:00
|
|
|
_ => {
|
|
|
|
|
self.bump();
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
}
|
2019-11-03 10:54:23 +01:00
|
|
|
// String was not terminated.
|
2019-05-06 10:53:40 +02:00
|
|
|
false
|
|
|
|
|
}
|
|
|
|
|
|
2019-10-26 18:12:58 +02:00
|
|
|
/// Eats double-quoted string and returns true
|
|
|
|
|
/// if string is terminated.
|
2019-05-06 10:53:40 +02:00
|
|
|
fn double_quoted_string(&mut self) -> bool {
|
|
|
|
|
debug_assert!(self.prev() == '"');
|
2019-11-03 10:55:05 +01:00
|
|
|
while let Some(c) = self.bump() {
|
|
|
|
|
match c {
|
2019-05-06 10:53:40 +02:00
|
|
|
'"' => {
|
|
|
|
|
return true;
|
|
|
|
|
}
|
2019-11-03 10:55:05 +01:00
|
|
|
'\\' if self.first() == '\\' || self.first() == '"' => {
|
|
|
|
|
// Bump again to skip escaped character.
|
2019-05-06 10:53:40 +02:00
|
|
|
self.bump();
|
|
|
|
|
}
|
|
|
|
|
_ => (),
|
|
|
|
|
}
|
|
|
|
|
}
|
2019-11-03 10:55:05 +01:00
|
|
|
// End of file reached.
|
|
|
|
|
false
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
|
|
|
|
|
2020-05-29 17:37:16 +02:00
|
|
|
/// Eats the double-quoted string and returns `n_hashes` and an error if encountered.
|
|
|
|
|
fn raw_double_quoted_string(&mut self, prefix_len: usize) -> (u16, Option<RawStrError>) {
|
|
|
|
|
// Wrap the actual function to handle the error with too many hashes.
|
|
|
|
|
// This way, it eats the whole raw string.
|
|
|
|
|
let (n_hashes, err) = self.raw_string_unvalidated(prefix_len);
|
|
|
|
|
// Only up to 65535 `#`s are allowed in raw strings
|
|
|
|
|
match u16::try_from(n_hashes) {
|
|
|
|
|
Ok(num) => (num, err),
|
|
|
|
|
// We lie about the number of hashes here :P
|
|
|
|
|
Err(_) => (0, Some(RawStrError::TooManyDelimiters { found: n_hashes })),
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
fn raw_string_unvalidated(&mut self, prefix_len: usize) -> (usize, Option<RawStrError>) {
|
2019-05-06 10:53:40 +02:00
|
|
|
debug_assert!(self.prev() == 'r');
|
2020-03-28 06:46:20 +01:00
|
|
|
let start_pos = self.len_consumed();
|
2020-05-29 17:37:16 +02:00
|
|
|
let mut possible_terminator_offset = None;
|
|
|
|
|
let mut max_hashes = 0;
|
2019-11-03 10:55:50 +01:00
|
|
|
|
2019-10-26 18:12:58 +02:00
|
|
|
// Count opening '#' symbols.
|
2020-03-28 06:46:20 +01:00
|
|
|
let n_start_hashes = self.eat_while(|c| c == '#');
|
2019-11-03 10:55:50 +01:00
|
|
|
|
|
|
|
|
// Check that string is started.
|
|
|
|
|
match self.bump() {
|
2020-05-29 17:37:16 +02:00
|
|
|
Some('"') => (),
|
|
|
|
|
c => {
|
|
|
|
|
let c = c.unwrap_or(EOF_CHAR);
|
|
|
|
|
return (n_start_hashes, Some(RawStrError::InvalidStarter { bad_char: c }));
|
2020-03-28 06:46:20 +01:00
|
|
|
}
|
2019-11-03 10:55:50 +01:00
|
|
|
}
|
|
|
|
|
|
|
|
|
|
// Skip the string contents and on each '#' character met, check if this is
|
|
|
|
|
// a raw string termination.
|
2020-03-28 06:46:20 +01:00
|
|
|
loop {
|
2019-11-03 10:55:50 +01:00
|
|
|
self.eat_while(|c| c != '"');
|
|
|
|
|
|
|
|
|
|
if self.is_eof() {
|
2020-05-29 17:37:16 +02:00
|
|
|
return (
|
2020-03-28 06:46:20 +01:00
|
|
|
n_start_hashes,
|
2020-05-29 17:37:16 +02:00
|
|
|
Some(RawStrError::NoTerminator {
|
|
|
|
|
expected: n_start_hashes,
|
|
|
|
|
found: max_hashes,
|
|
|
|
|
possible_terminator_offset,
|
|
|
|
|
}),
|
|
|
|
|
);
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
|
|
|
|
|
2019-11-03 10:55:50 +01:00
|
|
|
// Eat closing double quote.
|
|
|
|
|
self.bump();
|
|
|
|
|
|
|
|
|
|
// Check that amount of closing '#' symbols
|
|
|
|
|
// is equal to the amount of opening ones.
|
2020-04-25 20:19:54 +02:00
|
|
|
// Note that this will not consume extra trailing `#` characters:
|
2020-05-29 17:37:16 +02:00
|
|
|
// `r###"abcde"####` is lexed as a `RawStr { n_hashes: 3 }`
|
2020-04-25 20:19:54 +02:00
|
|
|
// followed by a `#` token.
|
2020-03-28 06:46:20 +01:00
|
|
|
let mut hashes_left = n_start_hashes;
|
2019-11-03 10:55:50 +01:00
|
|
|
let is_closing_hash = |c| {
|
|
|
|
|
if c == '#' && hashes_left != 0 {
|
|
|
|
|
hashes_left -= 1;
|
|
|
|
|
true
|
|
|
|
|
} else {
|
|
|
|
|
false
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
2019-11-03 10:55:50 +01:00
|
|
|
};
|
2020-03-28 06:46:20 +01:00
|
|
|
let n_end_hashes = self.eat_while(is_closing_hash);
|
|
|
|
|
|
|
|
|
|
if n_end_hashes == n_start_hashes {
|
2020-05-29 17:37:16 +02:00
|
|
|
return (n_start_hashes, None);
|
2020-03-30 18:39:40 +02:00
|
|
|
} else if n_end_hashes > max_hashes {
|
2020-04-25 20:19:54 +02:00
|
|
|
// Keep track of possible terminators to give a hint about
|
|
|
|
|
// where there might be a missing terminator
|
2020-03-28 06:46:20 +01:00
|
|
|
possible_terminator_offset =
|
|
|
|
|
Some(self.len_consumed() - start_pos - n_end_hashes + prefix_len);
|
|
|
|
|
max_hashes = n_end_hashes;
|
|
|
|
|
}
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
fn eat_decimal_digits(&mut self) -> bool {
|
|
|
|
|
let mut has_digits = false;
|
|
|
|
|
loop {
|
2019-11-03 09:39:39 +01:00
|
|
|
match self.first() {
|
2019-05-06 10:53:40 +02:00
|
|
|
'_' => {
|
|
|
|
|
self.bump();
|
|
|
|
|
}
|
|
|
|
|
'0'..='9' => {
|
|
|
|
|
has_digits = true;
|
|
|
|
|
self.bump();
|
|
|
|
|
}
|
|
|
|
|
_ => break,
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
has_digits
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
fn eat_hexadecimal_digits(&mut self) -> bool {
|
|
|
|
|
let mut has_digits = false;
|
|
|
|
|
loop {
|
2019-11-03 09:39:39 +01:00
|
|
|
match self.first() {
|
2019-05-06 10:53:40 +02:00
|
|
|
'_' => {
|
|
|
|
|
self.bump();
|
|
|
|
|
}
|
|
|
|
|
'0'..='9' | 'a'..='f' | 'A'..='F' => {
|
|
|
|
|
has_digits = true;
|
|
|
|
|
self.bump();
|
|
|
|
|
}
|
|
|
|
|
_ => break,
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
has_digits
|
|
|
|
|
}
|
|
|
|
|
|
2019-11-03 09:43:47 +01:00
|
|
|
/// Eats the float exponent. Returns true if at least one digit was met,
|
|
|
|
|
/// and returns false otherwise.
|
|
|
|
|
fn eat_float_exponent(&mut self) -> bool {
|
2019-05-06 10:53:40 +02:00
|
|
|
debug_assert!(self.prev() == 'e' || self.prev() == 'E');
|
2019-11-03 09:39:39 +01:00
|
|
|
if self.first() == '-' || self.first() == '+' {
|
2019-05-06 10:53:40 +02:00
|
|
|
self.bump();
|
|
|
|
|
}
|
2019-11-03 09:43:47 +01:00
|
|
|
self.eat_decimal_digits()
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
|
|
|
|
|
2019-11-03 09:42:08 +01:00
|
|
|
// Eats the suffix of the literal, e.g. "_u8".
|
2019-05-06 10:53:40 +02:00
|
|
|
fn eat_literal_suffix(&mut self) {
|
2019-11-03 09:42:08 +01:00
|
|
|
self.eat_identifier();
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
// Eats the identifier.
|
|
|
|
|
fn eat_identifier(&mut self) {
|
|
|
|
|
if !is_id_start(self.first()) {
|
2019-05-06 10:53:40 +02:00
|
|
|
return;
|
|
|
|
|
}
|
|
|
|
|
self.bump();
|
|
|
|
|
|
2019-11-03 09:42:08 +01:00
|
|
|
self.eat_while(is_id_continue);
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
/// Eats symbols while predicate returns true or until the end of file is reached.
|
|
|
|
|
/// Returns amount of eaten symbols.
|
|
|
|
|
fn eat_while<F>(&mut self, mut predicate: F) -> usize
|
|
|
|
|
where
|
2019-12-22 23:42:04 +01:00
|
|
|
F: FnMut(char) -> bool,
|
2019-11-03 09:42:08 +01:00
|
|
|
{
|
|
|
|
|
let mut eaten: usize = 0;
|
|
|
|
|
while predicate(self.first()) && !self.is_eof() {
|
|
|
|
|
eaten += 1;
|
2019-05-06 10:53:40 +02:00
|
|
|
self.bump();
|
|
|
|
|
}
|
2019-11-03 09:42:08 +01:00
|
|
|
|
|
|
|
|
eaten
|
2019-05-06 10:53:40 +02:00
|
|
|
}
|
|
|
|
|
}
|