Do what write does and optimize for the most likely case:
slices are much smaller than the buffer. If a slice does not fit
completely in the remaining capacity of the buffer, it is left out
rather than buffered partially. Special treatment is only left for
oversized slices that are written directly to the underlying writer.
Now that BufWriter always claims to support vectored writes,
look through it at the wrapped writer to decide whether to
use vectored writes for LineWriter.
If the underlying writer does not support efficient vectored output,
do it differently: always try to coalesce the slices in the buffer
until one comes that does not fit entirely. Flush the buffer before
the first slice if needed.
Stabilize clamp
Tracking issue: https://github.com/rust-lang/rust/issues/44095
Clamp has been merged and unstable for about a year and a half now. How do we feel about stabilizing this?
std: Update the bactrace crate submodule
This commit updates the `library/backtrace` submodule which primarily
pulls in support for split-debuginfo on macOS, avoiding the need for
`dsymutil` to get run to get line numbers and filenames in backtraces.
rustc_expand: Mark inner `#![test]` attributes as soft-unstable
Custom inner attributes are feature gated (https://github.com/rust-lang/rust/issues/54726) except for attributes having name `test` literally, which are not gated for historical reasons.
`#![test]` is an inner proc macro attribute, so it has all the issues described in https://github.com/rust-lang/rust/issues/54726 too.
This PR gates it with the `soft_unstable` lint.
This commit updates the `library/backtrace` submodule which primarily
pulls in support for split-debuginfo on macOS, avoiding the need for
`dsymutil` to get run to get line numbers and filenames in backtraces.
unix/weak: pass arguments to syscall at the given type
Given that we know the type the argument should have, it seems a bit strange not to use that information.
r? `@m-ou-se` `@cuviper`
Add lint for panic!("{}")
This adds a lint that warns about `panic!("{}")`.
`panic!(msg)` invocations with a single argument use their argument as panic payload literally, without using it as a format string. The same holds for `assert!(expr, msg)`.
This lints checks if `msg` is a string literal (after expansion), and warns in case it contained braces. It suggests to insert `"{}", ` to use the message literally, or to add arguments to use it as a format string.
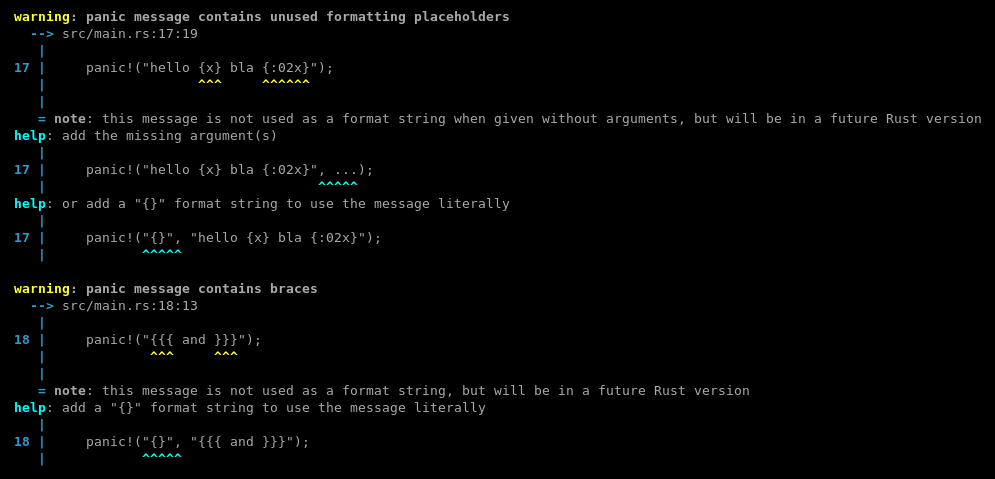
This lint is also a good starting point for adding warnings about `panic!(not_a_string)` later, once [`panic_any()`](https://github.com/rust-lang/rust/pull/74622) becomes a stable alternative.
Fix typo in `std::io::Write` docs
These referred to a “`Write`er”—extra *e*. Presumably a copy-paste
holdover from “`Read`er”.
Test Plan:
Running ``git grep '`\?[Ww]rite`\?er'`` no longer finds any results.
wchargin-branch: io-write-docs
Tighten the bounds on atomic Ordering in std::sys::unix::weak::Weak
This moves reading this from multiple SeqCst reads to Relaxed read + Acquire fence if we are actually going to use the data.
Would love to avoid the Acquire fence, but doing so would need Ordering::Consume, which neither Rust, nor LLVM supports (a shame, since this fence is hardly free on ARM, which is what I was hoping to improve).
r? ``@Amanieu`` (Sorry for always picking you, but I know a lot of people wouldn't feel comfortable reviewing atomic ordering changes)
linux: try to use libc getrandom to allow interposition
We'll try to use a weak `getrandom` symbol first, because that allows
things like `LD_PRELOAD` interposition. For example, perf measurements
might want to disable randomness to get reproducible results. If the
weak symbol is not found, we fall back to a raw `SYS_getrandom` call.
Updated the list of white-listed target features for x86
This PR both adds in-source documentation on what to look out for when adding a new (X86) feature set and [adds all that are detectable at run-time in Rust stable as of 1.27.0](https://github.com/rust-lang/stdarch/blob/master/crates/std_detect/src/detect/arch/x86.rs).
This should only enable the use of the corresponding LLVM intrinsics.
Actual intrinsics need to be added separately in rust-lang/stdarch.
It also re-orders the run-time-detect test statements to be more consistent
with the actual list of intrinsics whitelisted and removes underscores not present
in the actual names (which might be mistaken as being part of the name)
The reference for LLVM's feature names used is [this file](https://github.com/llvm/llvm-project/blob/master/llvm/include/llvm/Support/X86TargetParser.def).
This PR was motivated as the compiler end's part for allowing #67329 to be adressed over on rust-lang/stdarch
These referred to a “`Write`er”—extra *e*. Presumably a copy-paste
holdover from “`Read`er”.
Test Plan:
Running ``git grep '`\?[Ww]rite`\?er'`` no longer finds any results.
wchargin-branch: io-write-docs
Rollup of 9 pull requests
Successful merges:
- #77939 (Ensure that the source code display is working with DOS backline)
- #78138 (Upgrade dlmalloc to version 0.2)
- #78967 (Make codegen tests compatible with extra inlining)
- #79027 (Limit storage duration of inlined always live locals)
- #79077 (document that __rust_alloc is also magic to our LLVM fork)
- #79088 (clarify `span_label` documentation)
- #79097 (Code block invalid html tag lint)
- #79105 (std: Fix test `symlink_hard_link` on Windows)
- #79107 (build-manifest: strip newline from rustc version)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
std: Fix test `symlink_hard_link` on Windows
The test was introduced in https://github.com/rust-lang/rust/pull/78026 and fails depending on Windows version and admin rights.
Other similar tests check for symlink creation permissions before doing anything, this PR performs the same check for `symlink_hard_link` as well.
Upgrade dlmalloc to version 0.2
In preparation of adding dynamic memory management support for SGXv2-enabled platforms, the dlmalloc crate has been refactored. More specifically, support has been added to implement platform specification outside of the dlmalloc crate. (see https://github.com/alexcrichton/dlmalloc-rs/pull/15)
This PR upgrades dlmalloc to version 0.2 for the `wasm` and `sgx` targets.
As the dlmalloc changes have received a positive review, but have not been merged yet, this PR contains a commit to prevent tidy from aborting CI prematurely.
cc: `@jethrogb`
Make the libstd build script smaller
Of all sysroot crates currently only compiler_builtins, miniz_oxide and std require a build script. compiler_builtins uses to conditionally enable certain features and possibly compile a C version ([source](63ccaf11f0/build.rs)), miniz_oxide only uses it to detect if liballoc is supported as the MSRV is 1.34.0 instead of the 1.36.0 which stabilized liballoc ([source](28514ec09f/miniz_oxide/build.rs)). std now only uses it to enable `freebsd12` when the `RUST_STD_FREEBSD_12_ABI` env var is set, to determine if `restricted-std` should be set, to set the `STD_ENV_ARCH` env var identical to `CARGO_CFG_TARGET_ARCH`, and to unconditionally enable `backtrace_in_libstd`.
If all build scripts were to be removed, it would be possible for rustc to completely compile it's own sysroot. It currently requires a rustc version that already has an available libstd to compile the build scripts. If rustc can completely compile it's own sysroot, rustbuild could be simplified to not forcefully use the bootstrap compiler for build scripts.
`@rustbot` modify labels: +T-compiler +libs-impl
We'll try to use a weak `getrandom` symbol first, because that allows
things like `LD_PRELOAD` interposition. For example, perf measurements
might want to disable randomness to get reproducible results. If the
weak symbol is not found, we fall back to a raw `SYS_getrandom` call.
Simplify output capturing
This is a sequence of incremental improvements to the unstable/internal `set_panic` and `set_print` mechanism used by the `test` crate:
1. Remove the `LocalOutput` trait and use `Arc<Mutex<dyn Write>>` instead of `Box<dyn LocalOutput>`. In practice, all implementations of `LocalOutput` were just `Arc<Mutex<..>>`. This simplifies some logic and removes all custom `Sink` implementations such as `library/test/src/helpers/sink.rs`. Also removes a layer of indirection, as the outermost `Box` is now gone. It also means that locking now happens per `write_fmt`, not per individual `write` within. (So `"{} {}\n"` now results in one `lock()`, not four or more.)
2. Since in all cases the `dyn Write`s were just `Vec<u8>`s, replace the type with `Arc<Mutex<Vec<u8>>>`. This simplifies things more, as error handling and flushing can be removed now. This also removes the hack needed in the default panic handler to make this work with `::realstd`, as (unlike `Write`) `Vec<u8>` is from `alloc`, not `std`.
3. Replace the `RefCell`s by regular `Cell`s. The `RefCell`s were mostly used as `mem::replace(&mut *cell.borrow_mut(), something)`, which is just `Cell::replace`. This removes an unecessary bookkeeping and makes the code a bit easier to read.
4. Merge `set_panic` and `set_print` into a single `set_output_capture`. Neither the test crate nor rustc (the only users of this feature) have a use for using these separately. Merging them simplifies things even more. This uses a new function name and feature name, to make it clearer this is internal and not supposed to be used by other crates.
Might be easier to review per commit.
Rename/Deprecate LayoutErr in favor of LayoutError
Implements rust-lang/wg-allocators#73.
This patch renames LayoutErr to LayoutError, and uses a type alias to support users using the old name.
The new name will be instantly stable in release 1.49 (current nightly), the type alias will become deprecated in release 1.51 (so that when the current nightly is 1.51, 1.49 will be stable).
This is the only error type in `std` that ends in `Err` rather than `Error`, if this PR lands all stdlib error types will end in `Error` 🥰
Fix an intrinsic invocation on threaded wasm
This looks like it was forgotten to get updated in #74482 and wasm with
threads isn't built on CI so we didn't catch this by accident.
specialize io::copy to use copy_file_range, splice or sendfile
Fixes#74426.
Also covers #60689 but only as an optimization instead of an official API.
The specialization only covers std-owned structs so it should avoid the problems with #71091
Currently linux-only but it should be generalizable to other unix systems that have sendfile/sosplice and similar.
There is a bit of optimization potential around the syscall count. Right now it may end up doing more syscalls than the naive copy loop when doing short (<8KiB) copies between file descriptors.
The test case executes the following:
```
[pid 103776] statx(3, "", AT_STATX_SYNC_AS_STAT|AT_EMPTY_PATH, STATX_ALL, {stx_mask=STATX_ALL|STATX_MNT_ID, stx_attributes=0, stx_mode=S_IFREG|0644, stx_size=17, ...}) = 0
[pid 103776] write(4, "wxyz", 4) = 4
[pid 103776] write(4, "iklmn", 5) = 5
[pid 103776] copy_file_range(3, NULL, 4, NULL, 5, 0) = 5
```
0-1 `stat` calls to identify the source file type. 0 if the type can be inferred from the struct from which the FD was extracted
𝖬 `write` to drain the `BufReader`/`BufWriter` wrappers. only happen when buffers are present. 𝖬 ≾ number of wrappers present. If there is a write buffer it may absorb the read buffer contents first so only result in a single write. Vectored writes would also be an option but that would require more invasive changes to `BufWriter`.
𝖭 `copy_file_range`/`splice`/`sendfile` until file size, EOF or the byte limit from `Take` is reached. This should generally be *much* more efficient than the read-write loop and also have other benefits such as DMA offload or extent sharing.
## Benchmarks
```
OLD
test io::tests::bench_file_to_file_copy ... bench: 21,002 ns/iter (+/- 750) = 6240 MB/s [ext4]
test io::tests::bench_file_to_file_copy ... bench: 35,704 ns/iter (+/- 1,108) = 3671 MB/s [btrfs]
test io::tests::bench_file_to_socket_copy ... bench: 57,002 ns/iter (+/- 4,205) = 2299 MB/s
test io::tests::bench_socket_pipe_socket_copy ... bench: 142,640 ns/iter (+/- 77,851) = 918 MB/s
NEW
test io::tests::bench_file_to_file_copy ... bench: 14,745 ns/iter (+/- 519) = 8889 MB/s [ext4]
test io::tests::bench_file_to_file_copy ... bench: 6,128 ns/iter (+/- 227) = 21389 MB/s [btrfs]
test io::tests::bench_file_to_socket_copy ... bench: 13,767 ns/iter (+/- 3,767) = 9520 MB/s
test io::tests::bench_socket_pipe_socket_copy ... bench: 26,471 ns/iter (+/- 6,412) = 4951 MB/s
```
Previously EOVERFLOW handling was only applied for io::copy specialization
but not for fs::copy sharing the same code.
Additionally we lower the chunk size to 1GB since we have a user report
that older kernels may return EINVAL when passing 0x8000_0000
but smaller values succeed.
Android builds use feature level 14, the libc wrapper for splice is gated
on feature level 21+ so we have to invoke the syscall directly.
Additionally the emulator doesn't seem to support it so we also have to
add ENOSYS checks.
Update thread and futex APIs to work with Emscripten
This updates the thread and futex APIs in `std` to match the APIs exposed by
Emscripten. This allows threads to run on `wasm32-unknown-emscripten` and the
thread parker to compile without errors related to the missing `futex` module.
To make use of this, Rust code must be compiled with `-C target-feature=atomics`
and Emscripten must link with `-pthread`.
I have confirmed this works well locally when building multithreaded crates.
Attempting to enable `std` thread tests currently fails for seemingly obscure
reasons and Emscripten is currently disabled in CI, so further work is needed to
have proper test coverage here.
This updates the thread and futex APIs in `std` to match the APIs exposed by
Emscripten. This allows threads to run on `wasm32-unknown-emscripten` and the
thread parker to compile without errors related to the missing `futex` module.
To make use of this, Rust code must be compiled with `-C target-feature=atomics`
and Emscripten must link with `-pthread`.
I have confirmed this works well locally when building multithreaded crates.
Attempting to enable `std` thread tests currently fails for seemingly obscure
reasons and Emscripten is currently disabled in CI, so further work is needed to
have proper test coverage here.
Duration::zero() -> Duration::ZERO
In review for #72790, whether or not a constant or a function should be favored for `#![feature(duration_zero)]` was seen as an open question. In https://github.com/rust-lang/rust/issues/73544#issuecomment-691701670 an invitation was opened to either stabilize the methods or propose a switch to the constant value, supplemented with reasoning. Followup comments suggested community preference leans towards the const ZERO, which would be reason enough.
ZERO also "makes sense" beside existing associated consts for Duration. It is ever so slightly awkward to have a series of constants specifying 1 of various units but leave 0 as a method, especially when they are side-by-side in code. It seems unintuitive for the one non-dynamic value (that isn't from Default) to be not-a-const, which could hurt discoverability of the associated constants overall. Elsewhere in `std`, methods for obtaining a constant value were even deprecated, as seen with [std::u32::min_value](https://doc.rust-lang.org/std/primitive.u32.html#method.min_value).
Most importantly, ZERO costs less to use. A match supports a const pattern, but const fn can only be used if evaluated through a const context such as an inline `const { const_fn() }` or a `const NAME: T = const_fn()` declaration elsewhere. Likewise, while https://github.com/rust-lang/rust/issues/73544#issuecomment-691949373 notes `Duration::zero()` can optimize to a constant value, "can" is not "will". Only const contexts have a strong promise of such. Even without that in mind, the comment in question still leans in favor of the constant for simplicity. As it costs less for a developer to use, may cost less to optimize, and seems to have more of a community consensus for it, the associated const seems best.
r? ```@LukasKalbertodt```
The discussion seems to have resolved that this lint is a bit "noisy" in
that applying it in all places would result in a reduction in
readability.
A few of the trivial functions (like `Path::new`) are fine to leave
outside of closures.
The general rule seems to be that anything that is obviously an
allocation (`Box`, `Vec`, `vec![]`) should be in a closure, even if it
is a 0-sized allocation.
It was only ever used with Vec<u8> anyway. This simplifies some things.
- It no longer needs to be flushed, because that's a no-op anyway for
a Vec<u8>.
- Writing to a Vec<u8> never fails.
- No #[cfg(test)] code is needed anymore to use `realstd` instead of
`std`, because Vec comes from alloc, not std (like Write).
Define `fs::hard_link` to not follow symlinks.
POSIX leaves it [implementation-defined] whether `link` follows symlinks.
In practice, for example, on Linux it does not and on FreeBSD it does.
So, switch to `linkat`, so that we can pick a behavior rather than
depending on OS defaults.
Pick the option to not follow symlinks. This is somewhat arbitrary, but
seems the less surprising choice because hard linking is a very
low-level feature which requires the source and destination to be on
the same mounted filesystem, and following a symbolic link could end
up in a different mounted filesystem.
[implementation-defined]: https://pubs.opengroup.org/onlinepubs/9699919799/functions/link.html
Refactor `get_first_two_components` to `get_next_component`.
Fixes the following behaviour of `parse_prefix`:
- series of separator bytes in a prefix are correctly parsed as a single separator
- device namespace prefixes correctly recognize both `\\` and `/` as separators
Use Intra-doc links for std::io::buffered
Helps with #75080. I used the implicit link style for intrinsics, as that was what `minnumf32` and others already had.
``@rustbot`` modify labels: T-doc, A-intra-doc-links
r? ``@jyn514``
`#![deny(unsafe_op_in_unsafe_fn)]` in sys/hermit
Partial fix of #73904.
This encloses ``unsafe`` operations in ``unsafe fn`` in ``sys/hermit``.
Some unsafe blocks are not well documented because some system-based functions lack documents.
Partially fix#55002, deprecate in another release
Co-authored-by: Ashley Mannix <kodraus@hey.com>
Update stable version for stabilize_spin_loop
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Use better example for spinlock
As suggested by KodrAus
Remove renamed_spin_loop already available in master
Fix spin loop example
fix various aliasing issues in the standard library
This fixes various cases where the standard library either used raw pointers after they were already invalidated by using the original reference again, or created raw pointers for one element of a slice and used it to access neighboring elements.
Add note to process::arg[s] that args shouldn't be escaped or quoted
This came out of discussion on [forum](https://users.rust-lang.org/t/how-to-get-full-output-from-command/50626), where I recently asked a question and it turned out that the problem was redundant quotation:
```rust
Command::new("rg")
.arg("\"pattern\"") // this will look for "pattern" with quotes included
```
This is something that has bitten me few times already (in multiple languages actually), so It'd be grateful to have it in the docs, even though it's not sctrictly Rust specific problem. Other users also agreed.
This can be really annoying to debug, because in many cases (inluding mine), quotes can be legal part of the argument, so the command doesn't fail, it just behaves unexpectedly. Not everybody (including me) knows that quotes around arguments are part of the shell and not part of the called program. Coincidentally, somoene had the same problem [yesterday](https://www.reddit.com/r/rust/comments/jkxelc/going_crazy_over_running_a_curl_process_from_rust/) on reddit.
I am not a native speaker, so I welcome any corrections or better formulation, I don't expect this to be merged as is. I was also reminded that this is platform/shell specific behaviour, but I didn't find a good way to formulate that briefly, any ideas welcome.
It's also my first PR here, so I am not sure I did everything correctly, I did this just from Github UI.
make exp_m1 and ln_1p examples more representative of use
With this PR, the examples for `exp_m1` would fail if `x.exp() - 1.0` is used instead of `x.exp_m1()`, and the examples for `ln_1p` would fail if `(x + 1.0).ln()` is used instead of `x.ln_1p()`.
Add std::panic::panic_any.
The discussion of #67984 lead to the conclusion that there should be a macro or function separate from `std::panic!()` for throwing arbitrary payloads, to make it possible to deprecate or disallow (in edition 2021) `std::panic!(arbitrary_payload)`.
Alternative names:
- `panic_with!(..)`
- ~~`start_unwind(..)`~~ (panicking doesn't always unwind)
- `throw!(..)`
- `panic_throwing!(..)`
- `panic_with_value(..)`
- `panic_value(..)`
- `panic_with(..)`
- `panic_box(..)`
- `panic(..)`
The equivalent (private, unstable) function in `libstd` is called `std::panicking::begin_panic`.
I suggest `panic_any`, because it allows for any (`Any + Send`) type.
_Tracking issue: #78500_
Uplift `temporary-cstring-as-ptr` lint from `clippy` into rustc
The general consensus seems to be that this lint covers a common enough mistake to warrant inclusion in rustc.
The diagnostic message might need some tweaking, as I'm not sure the use of second-person perspective matches the rest of rustc, but I'd like to hear others' thoughts on that.
(cc #53224).
r? `@oli-obk`
Capture output from threads spawned in tests
This is revival of #75172.
Original text:
> Fixes#42474.
>
> r? `@dtolnay` since you expressed interest in this, but feel free to redirect if you aren't the right person anymore.
---
Closes#75172.
Updated the added documentation in llvm_util.rs to note which copies of LLVM need to be inspected.
Removed avx512bf16 and avx512vp2intersect because they are unsupported before LLVM 9 with the build with external LLVM 8 being supported
Re-introduced detection testing previously removed for un-requestable features tsc and mmx
`#[deny(unsafe_op_in_unsafe_fn)]` in sys/wasm
This is part of #73904.
This encloses unsafe operations in unsafe fn in `libstd/sys/wasm`.
@rustbot modify labels: F-unsafe-block-in-unsafe-fn
`movbe` seems to not be a run-time detectable feature on x86.
It has thus been removed from the list.
It was only commented out to ease comparison against the full list.
This PR both adds in-source documentation on what to look out for
when adding a new (X86) feature set and adds all that are detectable at run-time in Rust stable
as of 1.27.0.
This should only enable the use of the corresponding LLVM intrinsics.
Actual intrinsics need to be added separately in rust-lang/stdarch.
It also re-orders the run-time-detect test statements to be more consistent
with the actual list of intrinsics whitelisted and removes underscores not present
in the actual names (which might be mistaken as being part of the name)
replace `#[allow_internal_unstable]` with `#[rustc_allow_const_fn_unstable]` for `const fn`s
`#[allow_internal_unstable]` is currently used to side-step feature gate and stability checks.
While it was originally only meant to be used only on macros, its use was expanded to `const fn`s.
This pr adds stricter checks for the usage of `#[allow_internal_unstable]` (only on macros) and introduces the `#[rustc_allow_const_fn_unstable]` attribute for usage on `const fn`s.
This pr does not change any of the functionality associated with the use of `#[allow_internal_unstable]` on macros or the usage of `#[rustc_allow_const_fn_unstable]` (instead of `#[allow_internal_unstable]`) on `const fn`s (see https://github.com/rust-lang/rust/issues/69399#issuecomment-712911540).
Note: The check for `#[rustc_allow_const_fn_unstable]` currently only validates that the attribute is used on a function, because I don't know how I would check if the function is a `const fn` at the place of the check. I therefore openend this as a 'draft pull request'.
Closesrust-lang/rust#69399
r? @oli-obk
Throw core::panic!("message") as &str instead of String.
This makes `core::panic!("message")` consistent with `std::panic!("message")`, which throws a `&str` and not a `String`.
This also makes any other panics from `core::panicking::panic` result in a `&str` rather than a `String`, which includes compiler-generated panics such as the panics generated for `mem::zeroed()`.
---
Demonstration:
```rust
use std::panic;
use std::any::Any;
fn main() {
panic::set_hook(Box::new(|panic_info| check(panic_info.payload())));
check(&*panic::catch_unwind(|| core::panic!("core")).unwrap_err());
check(&*panic::catch_unwind(|| std::panic!("std")).unwrap_err());
}
fn check(msg: &(dyn Any + Send)) {
if let Some(s) = msg.downcast_ref::<String>() {
println!("Got a String: {:?}", s);
} else if let Some(s) = msg.downcast_ref::<&str>() {
println!("Got a &str: {:?}", s);
}
}
```
Before:
```
Got a String: "core"
Got a String: "core"
Got a &str: "std"
Got a &str: "std"
```
After:
```
Got a &str: "core"
Got a &str: "core"
Got a &str: "std"
Got a &str: "std"
```
revise Hermit's mutex interface to support the behaviour of StaticMutex
rust-lang/rust#77147 simplifies things by splitting this Mutex type into two types matching the two use cases: StaticMutex and MovableMutex. To support the new behavior of StaticMutex, we move part of the mutex implementation into libstd.
The interface to the OS changed. Consequently, I removed a few functions, which aren't longer needed.
According to [the bionic status page], `linkat` has only been available
since API level 21. Since Android is based on Linux and Linux's `link`
doesn't follow symlinks, just use `link` on Android.
[the bionic status page]: https://android.googlesource.com/platform/bionic/+/master/docs/status.md
Duration::ZERO composes better with match and various other things,
at the cost of an occasional parens, and results in less work for the
optimizer, so let's use that instead.
This expands time's test suite to use more and in more places the
range of methods and constants added to Duration in recent
proposals for the sake of testing more API surface area and
improving legibility.
const keyword: brief paragraph on 'const fn'
`const fn` were mentioned in the title, but called "deterministic functions" which is not their main property (though at least currently it is a consequence of being const-evaluable). This adds a brief paragraph discussing them, also in the hopes of clarifying that they do *not* have any effect on run-time uses.
If pthread mutex initialization fails, the failure will go unnoticed unless
debug assertions are enabled. Any subsequent use of mutex will also silently
fail, since return values from lock & unlock operations are similarly checked
only through debug assertions.
In some implementations the mutex initialization requires a memory
allocation and so it does fail in practice.
Check that initialization succeeds to ensure that mutex guarantees
mutual exclusion.
Add std:🧵:available_concurrency
This PR adds a counterpart to [C++'s `std:🧵:hardware_concurrency`](https://en.cppreference.com/w/cpp/thread/thread/hardware_concurrency) to Rust, tracking issue https://github.com/rust-lang/rust/issues/74479.
cc/ `@rust-lang/libs`
## Motivation
Being able to know how many hardware threads a platform supports is a core part of building multi-threaded code. In C++ 11 this has become available through the [`std:🧵:hardware_concurrency`](https://en.cppreference.com/w/cpp/thread/thread/hardware_concurrency) API. Currently in Rust most of the ecosystem depends on the [`num_cpus` crate](https://docs.rs/num_cpus/1.13.0/num_cpus/) ([no.35 in top 500 crates](https://docs.google.com/spreadsheets/d/1wwahRMHG3buvnfHjmPQFU4Kyfq15oTwbfsuZpwHUKc4/edit#gid=1253069234)) to provide this functionality. This PR proposes an API to provide access to the number of hardware threads available on a given platform.
__edit (2020-07-24):__ The purpose of this PR is to provide a hint for how many threads to spawn to saturate the processor. There's value in introducing APIs for NUMA and Windows processor groups, but those are intentionally out of scope for this PR. See: https://github.com/rust-lang/rust/pull/74480#issuecomment-662116186.
## Naming
Discussing the naming of the API on Zulip surfaced two options:
- `std:🧵:hardware_concurrency`
- `std:🧵:hardware_threads`
Both options seemed acceptable, but overall people seem to gravitate the most towards `hardware_threads`. Additionally `@jonas-schievink` pointed out that the "hardware threads" terminology is well-established and is used in among other the [RISC-V specification](https://riscv.org/specifications/isa-spec-pdf/) (page 20):
> A component is termed a core if it contains an independent instruction fetch unit. A RISC-V-compatible core might support multiple RISC-V-compatible __hardware threads__, or harts, through multithreading.
It's also worth noting that [the original paper introducing C++'s `std::thread` submodule](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2007/n2320.html) unfortunately doesn't feature any discussion on the naming of `hardware_concurrency`, so we can't use that to help inform our decision here.
## Return type
An important consideration `@joshtriplett` brought up is that we don't want to default to `1` for platforms where the number of available threads cannot be retrieved. Instead we want to inform the users of the fact that we don't know and allow them to handle that case. Which is why this PR uses `Option<NonZeroUsize>` as its return type, where `None` is returned on platforms where we don't know the number of hardware threads available.
The reasoning for `NonZeroUsize` vs `usize` is that if the number of threads for a platform are known, they'll always be at least 1. As evidenced by the example the `NonZero*` family of APIs may currently not be the most ergonomic to use, but improving the ergonomics of them is something that I think we can address separately.
## Implementation
`@Mark-Simulacrum` pointed out that most of the code we wanted to expose here was already available under `libtest`. So this PR mostly moves the internal code of libtest into a public API.
Use posix_spawn() on unix if program is a path
Previously `Command::spawn` would fall back to the non-posix_spawn based
implementation if the `PATH` environment variable was possibly changed.
On systems with a modern (g)libc `posix_spawn()` can be significantly
faster. If program is a path itself the `PATH` environment variable is
not used for the lookup and it should be safe to use the
`posix_spawnp()` method. [1]
We found this, because we have a cli application that effectively runs a
lot of subprocesses. It would sometimes noticeably hang while printing
output. Profiling showed that the process was spending the majority of
time in the kernel's `copy_page_range` function while spawning
subprocesses. During this time the process is completely blocked from
running, explaining why users were reporting the cli app hanging.
Through this we discovered that `std::process::Command` has a fast and
slow path for process execution. The fast path is backed by
`posix_spawnp()` and the slow path by fork/exec syscalls being called
explicitly. Using fork for process creation is supposed to be fast, but
it slows down as your process uses more memory. It's not because the
kernel copies the actual memory from the parent, but it does need to
copy the references to it (see `copy_page_range` above!). We ended up
using the slow path, because the command spawn implementation in falls
back to the slow path if it suspects the PATH environment variable was
changed.
Here is a smallish program demonstrating the slowdown before this code
change:
```
use std::process::Command;
use std::time::Instant;
fn main() {
let mut args = std::env::args().skip(1);
if let Some(size) = args.next() {
// Allocate some memory
let _xs: Vec<_> = std::iter::repeat(0)
.take(size.parse().expect("valid number"))
.collect();
let mut command = Command::new("/bin/sh");
command
.arg("-c")
.arg("echo hello");
if args.next().is_some() {
println!("Overriding PATH");
command.env("PATH", std::env::var("PATH").expect("PATH env var"));
}
let now = Instant::now();
let child = command
.spawn()
.expect("failed to execute process");
println!("Spawn took: {:?}", now.elapsed());
let output = child.wait_with_output().expect("failed to wait on process");
println!("Output: {:?}", output);
} else {
eprintln!("Usage: prog [size]");
std::process::exit(1);
}
()
}
```
Running it and passing different amounts of elements to use to allocate
memory shows that the time taken for `spawn()` can differ quite
significantly. In latter case the `posix_spawnp()` implementation is 30x
faster:
```
$ cargo run --release 10000000
...
Spawn took: 324.275µs
hello
$ cargo run --release 10000000 changepath
...
Overriding PATH
Spawn took: 2.346809ms
hello
$ cargo run --release 100000000
...
Spawn took: 387.842µs
hello
$ cargo run --release 100000000 changepath
...
Overriding PATH
Spawn took: 13.434677ms
hello
```
[1]: 5f72f9800b/posix/execvpe.c (L81)
Deny broken intra-doc links in linkchecker
Since rustdoc isn't warning about these links, check for them manually.
This also fixes the broken links that popped up from the lint.
stabilize union with 'ManuallyDrop' fields and 'impl Drop for Union'
As [discussed by @SimonSapin and @withoutboats](https://github.com/rust-lang/rust/issues/55149#issuecomment-634692020), this PR proposes to stabilize parts of the `untagged_union` feature gate:
* It will be possible to have a union with field type `ManuallyDrop<T>` for any `T`.
* While at it I propose we also stabilize `impl Drop for Union`; to my knowledge, there are no open concerns around this feature.
In the RFC discussion, we also talked about allowing `&mut T` as another non-`Copy` non-dropping type, but that felt to me like an overly specific exception so I figured we'd wait if there is actually any use for such a special case.
Some things remain unstable and still require the `untagged_union` feature gate:
* Union with fields that do not drop, are not `Copy`, and are not `ManuallyDrop<_>`. The reason to not stabilize this is to avoid semver concerns around libraries adding `Drop` implementations later. (This is already not fully semver compatible as, to my knowledge, the borrow checker will exploit the non-dropping nature of any type, but it seems prudent to avoid further increasing the amount of trouble adding an `impl Drop` can cause.)
Due to this, quite a few tests still need the `untagged_union` feature, but I think the ones where I could remove the feature flag provide good test coverage for the stable part.
Cc @rust-lang/lang
POSIX leaves it implementation-defined whether `link` follows symlinks.
In practice, for example, on Linux it does not and on FreeBSD it does.
So, switch to `linkat`, so that we can pick a behavior rather than
depending on OS defaults.
Pick the option to not follow symlinks. This is somewhat arbitrary, but
seems the less surprising choice because hard linking is a very
low-level feature which requires the source and destination to be on
the same mounted filesystem, and following a symbolic link could end
up in a different mounted filesystem.
Cleanup cloudabi mutexes and condvars
This gets rid of lots of unnecessary unsafety.
All the AtomicU32s were wrapped in UnsafeCell or UnsafeCell<MaybeUninit>, and raw pointers were used to get to the AtomicU32 inside. This change cleans that up by using AtomicU32 directly.
Also replaces a UnsafeCell<u32> by a safer Cell<u32>.
@rustbot modify labels: +C-cleanup
Static mutex is static
StaticMutex is only ever used with as a static (as the name already suggests). So it doesn't have to be generic over a lifetime, but can simply assume 'static.
This 'static lifetime guarantees the object is never moved, so this is no longer a manually checked requirement for unsafe calls to lock().
@rustbot modify labels: +T-libs +A-concurrency +C-cleanup
For backtrace, use StaticMutex instead of a raw sys Mutex.
The code used the very unsafe `sys::mutex::Mutex` directly, and built its own unlock-on-drop wrapper around it. The StaticMutex wrapper already provides that and is easier to use safely.
@rustbot modify labels: +T-libs +C-cleanup
Use futex-based thread-parker for Wasm32.
This uses the existing `sys_common/thread_parker/futex.rs` futex-based thread parker (that was already used for Linux) for wasm32 as well (if the wasm32 atomics target feature is enabled, which is not the case by default).
Wasm32 provides the basic futex operations as instructions: https://webassembly.github.io/threads/syntax/instructions.html
These are now exposed from `sys::futex::{futex_wait, futex_wake}`, just like on Linux. So, `thread_parker/futex.rs` stays completely unmodified.
Refactor io/buffered.rs into submodules
This pull request splits `BufWriter`, `BufReader`, `LineWriter`, and `LineWriterShim` (along with their associated tests) into separate submodules. It contains no functional changes. This change is being made in anticipation of adding another type of buffered writer which can be switched between line- and block-buffering mode.
Part of a series of pull requests resolving #60673.
StaticMutex is only ever used with as a static (as the name already
suggests). So it doesn't have to be generic over a lifetime, but can
simply assume 'static.
This 'static lifetime guarantees the object is never moved, so this is
no longer a manually checked requirement for unsafe calls to lock().
The comment said it's UB to call lock() while it is locked. That'd be
quite a useless Mutex. :) It was supposed to say 'locked by the same
thread', not just 'locked'.
warning: the operation is ineffective. Consider reducing it to
`self.segments()[0]`
--> library/std/src/net/ip.rs:1265:9
|
1265 | (self.segments()[0] & 0xffff) == 0xfe80
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(clippy::identity_op)]` on by default
= help: for further information visit
https://rust-lang.github.io/rust-clippy/master/index.html#identity_op
warning: the operation is ineffective. Consider reducing it to
`self.segments()[1]`
--> library/std/src/net/ip.rs:1266:16
|
1266 | && (self.segments()[1] & 0xffff) == 0
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= help: for further information visit
https://rust-lang.github.io/rust-clippy/master/index.html#identity_op
warning: the operation is ineffective. Consider reducing it to
`self.segments()[2]`
--> library/std/src/net/ip.rs:1267:16
|
1267 | && (self.segments()[2] & 0xffff) == 0
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= help: for further information visit
https://rust-lang.github.io/rust-clippy/master/index.html#identity_op
warning: the operation is ineffective. Consider reducing it to
`self.segments()[3]`
--> library/std/src/net/ip.rs:1268:16
|
1268 | && (self.segments()[3] & 0xffff) == 0
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= help: for further information visit
https://rust-lang.github.io/rust-clippy/master/index.html#identity_op
Signed-off-by: wcampbell <wcampbell1995@gmail.com>
warning: struct update has no effect, all the fields in the struct have
already been specified
--> library/std/src/net/addr.rs:367:19
|
367 | ..unsafe { mem::zeroed() }
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(clippy::needless_update)]` on by default
= help: for further information visit
https://rust-lang.github.io/rust-clippy/master/index.html#needless_update
Remove unsafety from sys/unsupported and add deny(unsafe_op_in_unsafe_fn).
Replacing `UnsafeCell`s by a `Cell`s simplifies things and makes the mutex and rwlock implementations safe. Other than that, only unsafety in strlen() contained unsafe code.
@rustbot modify labels: +F-unsafe-block-in-unsafe-fn +C-cleanup
Implement `AsRawFd` for `StdinLock` etc. on WASI.
WASI implements `AsRawFd` for `Stdin`, `Stdout`, and `Stderr`, so
implement it for `StdinLock`, `StdoutLock`, and `StderrLock` as well.
r? @alexcrichton
Avoid SeqCst or static mut in mach_timebase_info and QueryPerformanceFrequency caches
This patch went through a couple iterations but the end result is replacing a pattern where an `AtomicUsize` (updated with many SeqCst ops) guards a `static mut` with a single `AtomicU64` that is known to use 0 as a value indicating that it is not initialized.
The code in both places exists to cache values used in the conversion of Instants to Durations on macOS, iOS, and Windows.
I have no numbers to prove that this improves performance (It seems a little futile to benchmark something like this), but it's much simpler, safer, and in practice we'd expect it to be faster everywhere where Relaxed operations on AtomicU64 are cheaper than SeqCst operations on AtomicUsize, which is a lot of places.
Anyway, it also removes a bunch of unsafe code and greatly simplifies the logic, so IMO that alone would be worth it unless it was a regression.
If you want to take a look at the assembly output though, see https://godbolt.org/z/rbr6vn for x86_64, https://godbolt.org/z/cqcbqv for aarch64 (Note that this just the output of the mac side, but i'd expect the windows part to be the same and don't feel like doing another godbolt for it). There are several versions of this function in the godbolt:
- `info_new`: version in the current patch
- `info_less_new`: version in initial PR
- `info_original`: version currently in the tree
- `info_orig_but_better_orderings`: a version that just tries to change the original code's orderings from SeqCst to the (probably) minimal orderings required for soundness/correctness.
The biggest concern I have here is if we can use AtomicU64, or if there are targets that dont have it that this code supports. AFAICT: no. (If that changes in the future, it's easy enough to do something different for them)
r? `@Amanieu` because he caught a couple issues last time I tried to do a patch reducing orderings 😅
---
<details>
<summary>I rewrote this whole message so the original is inside here</summary>
I happened to notice the code we use for caching the result of mach_timebase_info uses SeqCst exclusively.
However, thinking a little more, it's actually pretty easy to avoid the static mut by packing the timebase info into an AtomicU64.
This entirely avoids needing to do the compare_exchange. The AtomicU64 can be read/written using Relaxed ops, which on current macos/ios platforms (x86_64/aarch64) have no overhead compared to direct loads/stores. This simplifies the code and makes it a lot safer too.
I have no numbers to prove that this improves performance (It seems a little futile to benchmark something like this), although it should do that on both targets it applies to.
That said, it also removes a bunch of unsafe code and simplifies the logic (arguably at least — there are only two states now, initialized or not), so I think it's a net win even without concrete numbers.
If you want to take a look at the assembly output though, see below. It has the new version, the original, and a version of the original with lower Orderings (which is still worse than the version in this PR)
- godbolt.org/z/obfqf9 x86_64-apple-darwin
- godbolt.org/z/Wz5cWc aarch64-unknown-linux-gnu (godbolt can't do aarch64-apple-ios but that doesn't matter here)
A different (and more efficient) option than this would be to just use the AtomicU64 and use the knowledge that after initialization the denominator should be nonzero... That felt like it's relying on too many things I'm not confident in, so I didn't want to do that.
</details>
rust-lang/rust#77147 simplifies things by splitting this Mutex type
into two types matching the two use cases: StaticMutex and MovableMutex.
To support the behavior of StaticMutex, we move part of the mutex
implementation into libstd.
doc: disambiguate stat in MetadataExt::as_raw_stat
A few architectures in `os::linux::raw` import `libc::stat`, rather than
defining that type directly. However, that also imports the _function_
called `stat`, which makes this doc link ambiguous:
error: `crate::os::linux::raw::stat` is both a struct and a function
--> library/std/src/os/linux/fs.rs:21:19
|
21 | /// [`stat`]: crate::os::linux::raw::stat
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^ ambiguous link
|
= note: `-D broken-intra-doc-links` implied by `-D warnings`
help: to link to the struct, prefix with the item type
|
21 | /// [`stat`]: struct@crate::os::linux::raw::stat
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
help: to link to the function, add parentheses
|
21 | /// [`stat`]: crate::os::linux::raw::stat()
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
We want the `struct`, so it's now prefixed accordingly.
Link to documentation-specific guidelines.
Changed contribution information URL because it's not obvious how to get from the current URL to the documentation-specific content.
The current URL points to this "Getting Started" page, which contains nothing specific about documentation[*] and instead launches into how to *build* `rustc` which is not a strict prerequisite for contributing documentation fixes:
* https://rustc-dev-guide.rust-lang.org/getting-started.html
[*] The most specific content is a "Writing documentation" bullet point which is not itself a link to anything (I guess a patch for that might be helpful too).
### Why?
Making this change will make it easier for people who wish to make small "drive by" documentation fixes (and read contribution guidelines ;) ) which I find are often how I start contributing to a project. (Exhibit A: https://github.com/rust-lang/rust/pull/77050 :) )
### Background
My impression is the change of content linked is an unintentional change due to a couple of other changes:
* Originally, the link pointed to `contributing.md` which started with a "table of contents" linking to each section. But the content in `contributing.md` was removed and replaced with a link to the "Getting Started" section here:
* 3f6928f1f6 (diff-6a3371457528722a734f3c51d9238c13L1)
But the changed link doesn't actually point to the equivalent content, which is now located here:
* https://rustc-dev-guide.rust-lang.org/contributing.html
(If the "Guide to Rustc Development" is now considered the canonical location of "How to Contribute" content it might be a good idea to merge some of the "Contributing" Introduction section into the "Getting Started" section.)
* This was then compounded by changing the link from `contributing.md` to `contributing.html` here:
* https://github.com/rust-lang/rust/pull/74037/files#diff-242481015141f373dcb178e93cffa850L88
In order to even find the new location of the previous `contributing.md` content I ended up needing to do a GitHub search of the `rust-lang` org for the phrase "Documentation improvements are very welcome". :D
{kind=link}
{kind=link}