Respect `-Z proc-macro-backtrace` flag for panics inside libproc_macro
Fixes#76270
Previously, any panic occuring during a call to a libproc_macro method
(e.g. calling `Ident::new` with an invalid identifier) would always
cause an ICE message to be printed.
Move:
- `src\test\ui\consts\const-nonzero.rs` to `library\core`
- `src\test\ui\consts\ascii.rs` to `library\core`
- `src\test\ui\consts\cow-is-borrowed` to `library\alloc`
Part of #76268
specialize some collection and iterator operations to run in-place
This is a rebase and update of #66383 which was closed due inactivity.
Recent rustc changes made the compile time regressions disappear, at least for webrender-wrench. Running a stage2 compile and the rustc-perf suite takes hours on the hardware I have at the moment, so I can't do much more than that.
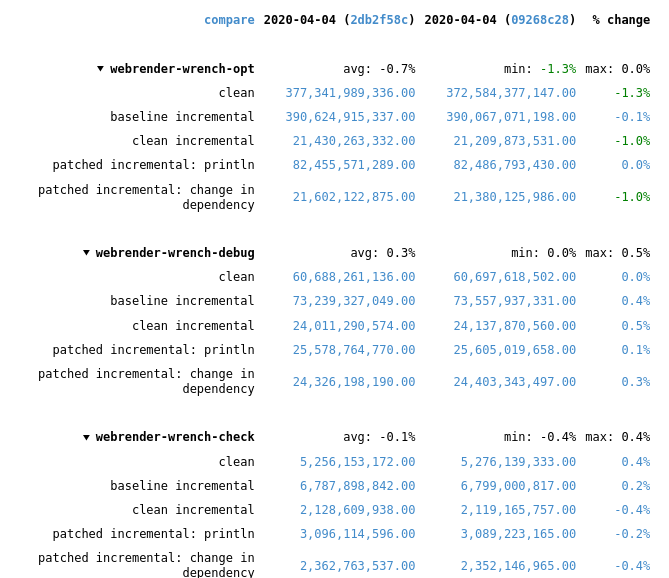
In the best case of the `vec::bench_in_place_recycle` synthetic microbenchmark these optimizations can provide a 15x speedup over the regular implementation which allocates a new vec for every benchmark iteration. [Benchmark results](https://gist.github.com/the8472/6d999b2d08a2bedf3b93f12112f96e2f). In real code the speedups are tiny, but it also depends on the allocator used, a system allocator that uses a process-wide mutex will benefit more than one with thread-local pools.
## What was changed
* `SpecExtend` which covered `from_iter` and `extend` specializations was split into separate traits
* `extend` and `from_iter` now reuse the `append_elements` if passed iterators are from slices.
* A preexisting `vec.into_iter().collect::<Vec<_>>()` optimization that passed through the original vec has been generalized further to also cover cases where the original has been partially drained.
* A chain of *Vec<T> / BinaryHeap<T> / Box<[T]>* `IntoIter`s through various iterator adapters collected into *Vec<U>* and *BinaryHeap<U>* will be performed in place as long as `T` and `U` have the same alignment and size and aren't ZSTs.
* To enable above specialization the unsafe, unstable `SourceIter` and `InPlaceIterable` traits have been added. The first allows reaching through the iterator pipeline to grab a pointer to the source memory. The latter is a marker that promises that the read pointer will advance as fast or faster than the write pointer and thus in-place operation is possible in the first place.
* `vec::IntoIter` implements `TrustedRandomAccess` for `T: Copy` to allow in-place collection when there is a `Zip` adapter in the iterator. TRA had to be made an unstable public trait to support this.
## In-place collectible adapters
* `Map`
* `MapWhile`
* `Filter`
* `FilterMap`
* `Fuse`
* `Skip`
* `SkipWhile`
* `Take`
* `TakeWhile`
* `Enumerate`
* `Zip` (left hand side only, `Copy` types only)
* `Peek`
* `Scan`
* `Inspect`
## Concerns
`vec.into_iter().filter(|_| false).collect()` will no longer return a vec with 0 capacity, instead it will return its original allocation. This avoids the cost of doing any allocation or deallocation but could lead to large allocations living longer than expected.
If that's not acceptable some resizing policy at the end of the attempted in-place collect would be necessary, which in the worst case could result in one more memcopy than the non-specialized case.
## Possible followup work
* split liballoc/vec.rs to remove `ignore-tidy-filelength`
* try to get trivial chains such as `vec.into_iter().skip(1).collect::<Vec<)>>()` to compile to a `memmove` (currently compiles to a pile of SIMD, see #69187 )
* improve up the traits so they can be reused by other crates, e.g. itertools. I think currently they're only good enough for internal use
* allow iterators sourced from a `HashSet` to be in-place collected into a `Vec`
The InPlaceIterable debug assert checks that the write pointer
did not advance beyond the read pointer. But TrustedRandomAccess
never advances the read pointer, thus triggering the assert.
Skip the assert if the source pointer did not change during iteration.
rustdoc: do not use plain summary for trait impls
Fixes#38386.
Fixes#48332.
Fixes#49430.
Fixes#62741.
Fixes#73474.
Unfortunately this is not quite ready to go because the newly-working links trigger a bunch of linkcheck failures. The failures are tough to fix because the links are resolved relative to the implementor, which could be anywhere in the module hierarchy.
(In the current docs, these links end up rendering as uninterpreted markdown syntax, so I don't think these failures are any worse than the status quo. It might be acceptable to just add them to the linkchecker whitelist.)
Ideally this could be fixed with intra-doc links ~~but it isn't working for me: I am currently investigating if it's possible to solve it this way.~~ Opened #73829.
EDIT: This is now ready!
The optimization meant that every extend code path had to emit llvm
IR for from_iter and extend spec_extend, which likely impacts
compile times while only improving a few edge-cases
switch to try_fold and segregate the drop handling to keep
collect::<Vec<u8>>() and similar optimizer-friendly
It comes at the cost of less accurate debug_asserts and code complexity
Fixes#76270
Previously, any panic occuring during a call to a libproc_macro method
(e.g. calling `Ident::new` with an invalid identifier) would always
cause an ICE message to be printed.
Convert many files to intra-doc links
Helps with https://github.com/rust-lang/rust/issues/75080
r? @poliorcetics
I recommend reviewing one commit at a time, but the diff is small enough you can do it all at once if you like :)
Applied `#![deny(unsafe_op_in_unsafe_fn)]` in library/std/src/wasi
partial fix for #73904
There are still more that was not applied in [mod.rs]( 38fab2ea92/library/std/src/sys/wasi/mod.rs) and that is due to its using files from `../unsupported`
like:
```
#[path = "../unsupported/cmath.rs"]
pub mod cmath;
```
Fix typos in vec try_reserve(_exact) docs
`try_reserve` and `try_reserve_exact` docs refer to calling `reserve` and `reserve_exact`.
`try_reserve_exact` example uses `try_reserve` method instead of `try_reserve_exact`.
Move to intra-doc links for library/core/src/iter/traits/iterator.rs
Helps with #75080.
@jyn514 We're almost finished with this issue. Thanks for mentoring. If you have other topics to work on just let me know, I will be around in Discord.
@rustbot modify labels: T-doc, A-intra-doc-links
Known issues:
* Link from `core` to `std` (#74481):
[`OsStr`]
[`String`]
[`VecDeque<T>`]
Rename and expose LoopState as ControlFlow
Basic PR for #75744. Addresses everything there except for documentation; lots of examples are probably a good idea.
Make all methods of `std::net::Ipv4Addr` const
Make the following methods of `std::net::Ipv4Addr` unstable const under the `const_ipv4` feature:
- `octets`
- `is_loopback`
- `is_private`
- `is_link_local`
- `is_global` (unstable)
- `is_shared` (unstable)
- `is_ietf_protocol_assignment` (unstable)
- `is_benchmarking` (unstable)
- `is_reserved` (unstable)
- `is_multicast`
- `is_broadcast`
- `is_documentation`
- `to_ipv6_compatible`
- `to_ipv6_mapped`
This would make all methods of `Ipv6Addr` const.
Of these methods, `is_global`, `is_broadcast`, `to_ipv6_compatible`, and `to_ipv6_mapped` require a change in implementation.
Part of #76205
Add `[T; N]::as_[mut_]slice`
Part of me trying to populate arrays with a couple of basic useful methods, like slices already have. The ability to add methods to arrays were added in #75212. Tracking issue: #76118
This adds:
```rust
impl<T, const N: usize> [T; N] {
pub fn as_slice(&self) -> &[T];
pub fn as_mut_slice(&mut self) -> &mut [T];
}
```
These methods are like the ones on `std::array::FixedSizeArray` and in the crate `arraytools`.
Add a note for Ipv4Addr::to_ipv6_compatible
Previous discussion: #75019
> I think adding a comment saying "This isn't typically the method you want; these addresses don't typically function on modern systems. Use `to_ipv6_mapped` instead." would be a good first step, whether this method gets marked as deprecated or not.
_Originally posted by @joshtriplett in https://github.com/rust-lang/rust/pull/75150#issuecomment-680267745_
- Use intra-doc links for `std::io` in `std::fs`
- Use intra-doc links for File::read in unix/ext/fs.rs
- Remove explicit intra-doc links for `true` in `net/addr.rs`
- Use intra-doc links in alloc/src/sync.rs
- Use intra-doc links in src/ascii.rs
- Switch to intra-doc links in alloc/rc.rs
- Use intra-doc links in core/pin.rs
- Use intra-doc links in std/prelude
- Use shorter links in `std/fs.rs`
`io` is already in scope.
flt2dec: properly handle uninitialized memory
The float-to-str code currently uses uninitialized memory incorrectly (see https://github.com/rust-lang/rust/issues/76092). This PR fixes that.
Specifically, that code used `&mut [T]` as "out references", but it would be incorrect for the caller to actually pass uninitialized memory. So the PR changes this to `&mut [MaybeUninit<T>]`, and then functions return a `&[T]` to the part of the buffer that they initialized (some functions already did that, indirectly via `&Formatted`, others were adjusted to return that buffer instead of just the initialized length).
What I particularly like about this is that it moves `unsafe` to the right place: previously, the outermost caller had to use `unsafe` to assert that things are initialized; now it is the functions that do the actual initializing which have the corresponding `unsafe` block when they call `MaybeUninit::slice_get_ref` (renamed in https://github.com/rust-lang/rust/pull/76217 to `slice_assume_init_ref`).
Reviewers please be aware that I have no idea how any of this code actually works. My changes were purely mechanical and type-driven. The test suite passes so I guess I didn't screw up badly...
Cc @sfackler this is somewhat related to your RFC, and possibly some of this code could benefit from (a generalized version of) the API you describe there. But for now I think what I did is "good enough".
Fixes https://github.com/rust-lang/rust/issues/76092.
`try_reserve` and `try_reserve_exact` docs refer to calling `reserve` and `reserve_exact`.
`try_reserve_exact` example uses `try_reserve` method instead of `try_reserve_exact`.
Make all methods of `std::net::Ipv6Addr` const
Make the following methods of `std::net::Ipv6Addr` unstable const under the `const_ipv6` feature:
- `segments`
- `is_unspecified`
- `is_loopback`
- `is_global` (unstable)
- `is_unique_local`
- `is_unicast_link_local_strict`
- `is_documentation`
- `multicast_scope`
- `is_multicast`
- `to_ipv4_mapped`
- `to_ipv4`
This would make all methods of `Ipv6Addr` const.
Changed the implementation of `is_unspecified` and `is_loopback` to use a `match` instead of `==`, all other methods did not require a change.
All these methods are dependent on `segments`, the current implementation of which requires unstable `const_fn_transmute` ([PR#75085](https://github.com/rust-lang/rust/pull/75085)).
Part of #76205
Move to intra-doc links for library/core/src/panic.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Link from `core` to `std` (#74481):
[`set_hook`]
[`String`]
Add more examples to lexicographic cmp on Iterators.
Given two arrays of T1 and T2, the most important rule of lexicographical comparison is that two arrays
of equal length will be compared until the first difference occured.
The examples provided only focuses on the second rule that says that the
shorter array will be filled with some T2 that is less than every T1.
Which is only possible because of the first rule.
Makes the following methods of `std::net::Ipv4Addr` unstable const under the `const_ipv4` feature:
- `is_global`
- `is_reserved`
- `is_broadcast`
- `to_ipv6_compatible`
- `to_ipv6_mapped`
This results in all methods of `Ipv4Addr` being const.
Also adds tests for these methods in a const context.
Make the following methods of `std::net::Ipv6Addr` unstable const under the `const_ipv6` feature:
- `segments`
- `is_unspecified`
- `is_loopback`
- `is_global` (unstable)
- `is_unique_local`
- `is_unicast_link_local_strict`
- `is_documentation`
- `multicast_scope`
- `is_multicast`
- `to_ipv4_mapped`
- `to_ipv4`
Changed the implementation of `is_unspecified` and `is_loopback` to use a `match` instead of `==`.
Part of #76205
Constify the following methods of `core::cmp::Ordering`:
- `reverse`
- `then`
Stabilizes these methods as const under the `const_ordering` feature.
Also adds a test for these methods in a const context.
Possible because of #49146 (Allow `if` and `match` in constants).
rename get_{ref, mut} to assume_init_{ref,mut} in Maybeuninit
References #63568
Rework with comments addressed from #66174
Have replaced most of the occurrences I've found, hopefully didn't miss out anything
r? @RalfJung
(thanks @danielhenrymantilla for the initial work on this)
This reverts commit 7e2548fe69.
Now I know why it was redefined: it seems like it's potentially because
of the orphan rule. Here are the error messages:
error[E0119]: conflicting implementations of trait `std::fmt::Debug` for type `!`:
--> src/primitive_docs.rs:236:1
|
6 | impl Debug for ! {
| ^^^^^^^^^^^^^^^^
|
= note: conflicting implementation in crate `core`:
- impl std::fmt::Debug for !;
error[E0117]: only traits defined in the current crate can be implemented for arbitrary types
--> src/primitive_docs.rs:236:1
|
6 | impl Debug for ! {
| ^^^^^^^^^^^^^^^-
| | |
| | `!` is not defined in the current crate
| impl doesn't use only types from inside the current crate
|
= note: define and implement a trait or new type instead
Make `cow_is_borrowed` methods const
Constify the following methods of `alloc::borrow::Cow`:
- `is_borrowed`
- `is_owned`
Analogous to the const methods `is_some` and `is_none` for Option, and `is_ok` and `is_err` for Result.
These methods are still unstable under `cow_is_borrowed`.
Possible because of #49146 (Allow if and match in constants).
Tracking issue: #65143
Move `#[cfg(test)]` modules into separate files to save recompiling the `std` crate
Implements an accepted proposal: https://github.com/rust-lang/compiler-team/issues/344
Some notes for reviewers:
* `mod tests` nested in `mod foo` in `mod bar`, I move `foo` to a new file, `tests` is a new file in foo: For example library/std/src/sys/sgx/abi/tls.rs
* `mod test` (not `mod tests`) also is moved.
* `mod benches` are moved.
* `mod tests` is placed before any `use` statements: The topic is discussed in https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/Code.20Style.20process
* Some files in cloudabi was changed too. But I notice copyright banners in those files, should we ping cloudabi people?
* I formatted files after moving tests around. I think that may make it easier to review :p .
* Some files don't need `ignore-tidy-filelength` anymore.
Get rid of bounds check in slice::chunks_exact() and related function…
…s during construction
LLVM can't figure out in
let rem = self.len() % chunk_size;
let len = self.len() - rem;
let (fst, snd) = self.split_at(len);
and
let rem = self.len() % chunk_size;
let (fst, snd) = self.split_at(rem);
that the index passed to split_at() is smaller than the slice length and
adds a bounds check plus panic for it.
Apart from removing the overhead of the bounds check this also allows
LLVM to optimize code around the ChunksExact iterator better.
Use intra-doc links for `core/src/slice.mod.rs`
partial help in #75080
r? @jyn514
- most are using primitive types links, which cannot be used with intra links at the moment
- also `std` cannot be referenced in any link, `std::ptr::NonNull` and `std::slice` could not be referenced
Add `-Z proc-macro-backtrace` to allow showing proc-macro panics
Fixes#75050
Previously, we would unconditionally suppress the panic hook during
proc-macro execution. This commit adds a new flag
`-Z proc-macro-backtrace`, which allows running the panic hook for
easier debugging.
Constify the following methods of `std::net::Ipv4Addr`:
- `octets`
- `is_loopback`
- `is_private`
- `is_link_local`
- `is_shared`
- `is_ietf_protocol_assignment`
- `is_benchmarking`
- `is_multicast`
- `is_documentation`
Also insta-stabilizes these methods as const.
Possible because of the stabilization of const integer arithmetic and control flow.
Fixes#75050
Previously, we would unconditionally suppress the panic hook during
proc-macro execution. This commit adds a new flag
-Z proc-macro-backtrace, which allows running the panic hook for
easier debugging.
Constify the following methods of `alloc::borrow::Cow`:
- `is_borrowed`
- `is_owned`
These methods are still unstable under `cow_is_borrowed`.
Possible because of #49146 (Allow if and match in constants).
Tracking issue: #65143
Make some Ordering methods const
Constify the following methods of `core::cmp::Ordering`:
- `reverse`
- `then`
Possible because of #49146 (Allow `if` and `match` in constants).
Tracking issue: #76113
LLVM can't figure out in
let rem = self.len() % chunk_size;
let len = self.len() - rem;
let (fst, snd) = self.split_at(len);
and
let rem = self.len() % chunk_size;
let (fst, snd) = self.split_at(rem);
that the index passed to split_at() is smaller than the slice length and
adds a bounds check plus panic for it.
Apart from removing the overhead of the bounds check this also allows
LLVM to optimize code around the ChunksExact iterator better.
These are unsafe variants of the non-unchecked functions and don't do
any bounds checking.
For the time being these are not public and only a preparation for the
following commit. Making it public and stabilization can follow later
and be discussed in https://github.com/rust-lang/rust/issues/76014 .
`alloc::slice` uses `core::slice` functions, documentation are copied
from there and the links as well without resolution. `crate::ptr...`
cannot be resolved in `alloc::slice`, but `ptr` itself is imported in
both `alloc::slice` and `core::slice`, so we used that instead.
vars() rather than vars function
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Use [xxx()] rather than the [xxx] function
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Env text representation of function intra-doc link
Suggested by @jyn514
Link join_paths in env doc for parity
Change xxx to env::xxx for lib env doc
Add link requsted by @jyn514
Fix doc build with same link
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Fix missing intra-doc link
Fix added whitespace in doc
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Add brackets for `join_paths`
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Use unused link join_paths
Removed same link for join_paths
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Remove unsed link join_paths
Move to intra-doc links for library/core/src/sync/atomic.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Link from core to std:
[`Arc`]
[`std:🧵:yield_now`]
[`std:🧵:sleep`]
[`std::sync::Mutex`]
Shorten liballoc doc intra link while readable
r? @jyn514
Do you want to reviews these sort of pull requests in the future? I might send a few of them while reading vec code.
The most important rule of lexicographical comparison is that two arrays
of equal length will be compared until the first difference occured.
The examples provided only focuses on the second rule that says that the
shorter array will be filled with some T2 that is less than every T.
Which is only possible because of the first rule.
Update compiler-builtins
Update the compiler-builtins dependency to include latest changes.
This allows for `aarch64-unknown-linux-musl` to pass all tests.
Fixes#57820 and fixes#46651
Substantial refactor to the design of LineWriter
# Preamble
This is the first in a series of pull requests designed to move forward with https://github.com/rust-lang/rust/issues/60673 (and the related [5 year old FIXME](ea7181b5f7/src/libstd/io/stdio.rs (L459-L461))), which calls for an update to `Stdout` such that it can be block-buffered rather than line-buffered under certain circumstances (such as a `tty`, or a user setting the mode with a function call). This pull request refactors the logic `LineWriter` into a `LineWriterShim`, which operates on a `BufWriter` by mutable reference, such that it is easy to invoke the line-writing logic on an existing `BufWriter` without having to construct a new `LineWriter`.
Additionally, fixes#72721
## A note on flushing
Because the word **flush** tends to be pretty overloaded in this discussion, I'm going to use the word **unbuffered** to refer to a `BufWriter` sending its data to the wrapped writer via `write`, without calling `flush` on it, and I'll be using **flushed** when referring to sending data via flush, which recursively writes the data all the way to the final sink.
For example, given a `T = BufWriter<BufWriter<File>>`, saying that `T` **unbuffers** its data means that it is sent to the inner `BufWriter`, but not necessarily to the `File`, whereas saying that `T` **flushes** its data means that causes it (via `Write::flush`) to be delivered all the way to `File`.
# Goals
Once it became clear (for reasons described below) that the best way to approach this would involve refactoring `LineWriter` to work more directly on `BufWriter`'s internals, I established the following design goals for the refactor:
- Do not duplicate logic with `BufWriter`. It's great at buffering and then unbuffering data, so use the existing logic as much as possible.
- Minimize superfluous copying of data into `BufWriter`'s buffer.
- Eliminate calls to `BufWriter::flush` and instead do the same thing as `BufWriter::write`, which is to only write to the wrapped writer (rather than flushing all the way down to the final data sink).
- Uphold the "at-most 1 write of new data" convention of `Write::write`
- Minimize or eliminate dropping errors (that is, eliminate the parts of the old design that threw away errors because `write` *must* report if any bytes were written)
- As much as possible, attempt to fully flush completed lines, and *not* flush partial lines. One of the advantages of this design is that, so long as we don't encounter lines larger than the `BufWriter`'s capacity, partial lines will never be unbuffered, while completed lines will *always* be unbuffered (with subsequent calls to `LineWriter::write` retrying failed writes before processing new data.
# Design
There are two major & related parts of the design.
First, a new internal stuct, `LineWriterShim`, is added. This struct implements all of the actual logic of line-writing in a `Write` implementation, but it only operates on an `&mut BufWriter`. This means that this shim can be constructed on-the-fly to apply line writing logic to an existing `BufWriter`. This is in fact how `LineWriter` has been updated to operate, and it is also how `Stdout` is being updated in my [development branch](https://github.com/Lucretiel/rust/tree/stdout-block-buffer) to switch which mode it wants to use at runtime.
[An example of how this looks in practice](f24f272df6/src/libstd/io/stdio.rs (L479-L484)
)
The second major part of the design that the line-buffering logic, implemented in `LineWriterShim`, has been updated to work slightly more directly on the internals of `BufWriter`. Mostly it makes us of the public interface—particularly `buffer()` and `get_mut()`—but it also controls the flushing of the buffer with `flush_buf` rather than `flush`, and it writes to the buffer infallibly with a new `write_to_buffer` method. This has several advantages:
- Data no longer has to round trip through the `BufWriter`'s buffer. If the user provides a complete line, that line is written directly to the inner writer (after ensuring the existing buffer is flushed).
- The conventional contract of `write`—that at-most 1 attempt to write new data is made—is much more cleanly upheld, because we don't have to perform fallible flushes and perform semi-complicated logic of trying to pretend errors at different stages didn't happen. Instead, after attempting to write lines directly to the buffer, we can infallibly add trailing data to the buffer without allowing any attempts to continue writing it to the `inner` writer.
- Perhaps most importantly, `LineWriter` *no longer performs a full flush on every line.* This makes its behavior much more consistent with `BufWriter`, which unbuffers data to its inner writer, without trying to flush it all the way to the final device. Previously, `LineWriter` had no choice but to use `flush` to ensure that the lines were unbuffered, but by writing directly to `inner` via `get_mut()` (when appropriate), we can use a more correct behavior.
## New(ish) line buffering logic
The logic for line writing has been cleaned up, as described above. It now follows this algorithm for `write`, with minor adjustments for `write_all` and `write_vectored`:
- Does our input data contain a newline?
- If no:
- simply use the regular `BufWriter::write` to write it; this will append it to the buffer and/or flush it as necessary based on how full the buffer is and how much input data there is.
- additionally, if the current buffer ends with `'\n'`, attempt to immediately flush it with `flush_buf` before calling `BufWriter::write` This reproduces the old `needs_flush` behavior and ensures completed lines are flushed as soon as possible. The reason we only check if the buffer *ends* with `'\n'` is discussed later.
- If yes:
- First, `flush_buf`
- Then use `bufwriter.get_mut().write()` to write the input data directly to the underlying writer, up to the last newline. Make at most one attempt at this.
- If it errors, return the error
- If it succeeds with a full write, add the remaining data (between the last newline and the end of the input) to the buffer. In order to uphold the "at-most 1 attempt to write new data" convention, no attempts are made to write this data to the inner writer (though obviously a subsequent write may immediately flush it, e.g., if it totally filled the buffer's capacity.
- If it only partially succeeds, buffer the data only up to the last newline. We do this to try to avoid writing partial lines to the inner writer where possible (that is, whenever the lines are shorter than the total buffer capacity).
While it was not my intention for this behavior to diverge from this existing `LineWriter` algorithm, this updated design emerged very naturally once `LineWriter` wasn't burdened with having to only operate via `BufWriter::flush`. There essentially two main changes to observable behavior:
- `flush` is no longer used to unbuffer lines. The are only written to the writer wrapped by `LineWriter`; this inner writer might do its own buffering. This change makes `LineWriter` consistent with the behavior of `BufWriter`. This is probably the most obvious user-visible change; it's the one I most expect to provoke issue reports, if any are provoked.
- Unless a line exceeds the capacity of the buffer, partial lines are not unbuffered (without the user manually calling flush). This is a less surprising behavior, and is enabled because `LineWriter` now has more precise control of what data is buffered and when it is unbuffered. I'd be surprised if anyone is relying on `LineWriter` unbuffering or flushing *partial* lines that are shorter than the capacity, so I'm not worried about this one.
None of these changes are inconsistent with any published documentation of `LineWriter`. Nonetheless, like all changes with user-facing behavior changes, this design will obviously have to be very carefully scrutinized.
# Alternative designs and design rationalle
The initial goal of this project was to provide a way for the `LineWriter` logic to be operable directly on a `BufWriter`, so that the updated `Stdout` doesn't need to do something convoluted like `enum { BufWriter, LineWriter }` (which ends up being ~~impossible~~ difficult to transition between states after being constructed). The design went through several iterations before arriving at the current draft.
The major first version simply involved adding methods like `write_line_buffered` to `BufWriter`; these would contain the actual logic of line-buffered writing, and would additionally have the advantages (described above) of operating directly on the internals of `BufWriter`. The idea was that `LineWriter` would simply call these methods, and the updated `Stdout` would use either `BufWriter::write` or `BufWriter::write_line_buffered`, depending on what mode it was in.
The major issue with this design is that it loses the ability to take advantage of the `io::Write` trait, which provides several useful default implementations of the various io methods, such as `write_fmt` and `write_all`, just using the core methods. For this reason, the `write_line_buffered` design was retained, but moved into a separate struct called `LineWriterShim` which operates on an `&mut LineWriter`. As part of this move, the logic was lightly retooled to not touch the innards of `BufWriter` directly, but instead to make use of the unexported helper methods like `flush_buf`.
The other design evolutions were mostly related to answering questions like "how much data should be buffered", "how should partial line writes be handled", etc. As much as possible I tried to answer these by emulating the current `LineWriter` logic (which, for example, retries partial line writes on subsequent calls to `write`) while still meeting the refactor design goals.
# Next steps
~Currently, this design fails a few `LineWriter` tests, mostly because they expect `LineWriter` to *fully* flush its content. There are also some changes to the way that `LineWriter` buffers data *after* writing completed lines, aimed at ensuring that partial lines are not unbuffered prematurely. I want to make sure I fully understand the intent behind these tests before I either update the test or update this design so that they pass.~
However, in the meantime I wanted to get this published so that feedback could start to accumulate on it. There's a lot of errata around how I arrived at this design that didn't really fit in this overlong document, so please ask questions about anything that confusing or unclear and hopefully I can explain more of the rationale that led to it.
# Test updates
This design required some tests to be updated; I've research the intent behind these tests (mostly via `git blame`) and updated them appropriately. Those changes are cataloged here.
- `test_line_buffer_fail_flush`: This test was added as a regression test for #32085, and is intended to assure that an errors from `flush` aren't propagated when preceded by a successful `write`. Because type of issue is no longer possible, because `write` calls `buffer.get_mut().write()` instead of `buffer.write(); buffer.flush();`, I'm simply removing this test entirely. Other, similar error invariants related to errors during write-retrying are handled in other test cases.
- `erroneous_flush_retried`: This test was added as a regression test for #37807, and was intended to ensure that flush-retrying (via `needs_flush`) and error-ignoring were being handled correctly (ironically, this issue was caused by the flush-error-ignoring, above). Half of that issue is not possible by design with this refactor, because we no longer make fallible i/o calls that might produce errors we have to ignore after unbuffering lines. The `should_flush` behavior is captured by checking for a trailing newline in the `LineWriter` buffer; this test now checks that behavior.
- `line_vectored`: changes here were pretty minor, mostly related to when partial lines are or aren't written. The old implementation of `write_vectored` used very complicated logic to precisely determine the location of the last newline and precisely write up to that point; this required doing several consecutive fallible writes, with all the complex error handling or ignoring issues that come with it. The updated design does at-most one write of a subset of total buffers (that is, it doesn't split in the middle of a buffer), even if that means writing partial lines. One of the major advantages of the new design is that the underlying vectored write operation on the device can be taken advantage of, even with small writes, so long as they include a newline; previously these were unconditionally buffered then written.
- `line_vectored_partial_and_errors`: Pretty similiar to `line_vectored`, above; this test is for basic error recovery in `write_vectored` for vectored writes. As previously discussed, the mocked behavior being tested for (errors ignored under certain circumstances) no occurs, so I've simplified the test while doing my best to retain its spirit.
Add InstrProfilingPlatformFuchsia.c to profiler_builtins
All other Platform files included in `llvm-project/compiler-rt` were
present, except Fuchsia.
Now that there is a functional end-to-end version of
`-Zinstrument-coverage`, I need to start building and testing
coverage-enabled Rust programs on Fuchsia, and this file is required.
r? @tmandry
FYI, @wesleywiser
Fix potential UB in align_offset doc examples
Currently it takes a pointer only to the first element in the array, this changes the code to take a pointer to the whole array.
miri can't catch this right now because it later calls `x.len()` which re-tags the pointer for the whole array.
https://github.com/rust-lang/miri/issues/1526#issuecomment-680897144
Abort when foreign exceptions are caught by catch_unwind
Prior to this PR, foreign exceptions were not caught by catch_unwind, and instead passed through invisibly. This represented a painful soundness hole in some libraries ([take_mut](https://github.com/Sgeo/take_mut/blob/master/src/lib.rs#L37)), which relied on `catch_unwind` to handle all possible exit paths from a closure.
With this PR, foreign exceptions are now caught by `catch_unwind` and will trigger an abort since catching foreign exceptions is currently UB according to the latest proposals by the FFI unwind project group.
cc @rust-lang/wg-ffi-unwind
All other Platform files included in `llvm-project/compiler-rt` were
present, except Fuchsia.
Now that there is a functional end-to-end version of
`-Zinstrument-coverage`, I need to start building and testing
coverage-enabled Rust programs on Fuchsia, and this file is required.
{kind=link}