Adjust Miri value visitor, and doc-comment layout components
I realized that I still didn't have quite the right intuition for how our `LayoutDetails` work, so I had to adjust the Miri value visitor to the things I understood better now. I also added some doc-comments to `LayoutDetails` as a hopefully canonical place to note such things.
The main visitor change is that we *first* look at all the fields (according to `FieldPlacement`), and *then* check the variants and handle `Multiple` appropriately. I did not quite realize how orthogonal "fields" and "variants" are.
I also moved the check for the scalar ABI to *after* checking all the fields; this leads to better (more type-driven) error messages.
And it looks like we can finally remove that magic hack for `ty::Generator`. :D
r? @oli-obk for the Miri/visitor changes and @eddyb for the layout docs
The Miri PR is at: https://github.com/rust-lang/miri/pull/1178
Clean up TypeFlags
* Add a new method `has_infer_types_or_consts` that's used instead of `has_infer_types` most of the time, since there's generally no reason to only consider types.
* Remove `has_closure_types`/`HAS_TY_CLOSURE`, because closures are no longer implicitly linked to the `InferCtxt`.
* Reorder flags to group similar ones together
* Make some flags more granular
* Compute `HAS_FREE_LOCAL_NAMES` from the other flags
* Add some more doc comments
`--explain` disambiguates no long description and invalid error codes
Closes#44710
First code contribution here, so feedback is very much appreciated!
cc @zackmdavis
cc @Mark-Simulacrum
rustc_metadata: Load metadata for indirect macro-only dependencies
Imagine this dependency chain between crates
```
Executable crate -> Library crate -> Macro crate
```
where "Library crate" uses the macros from "Macro crate" for some code generation, but doesn't reexport them any further.
Currently, when compiling "Executable crate" we don't even load metadata for it, because why would we want to load any metadata from "Macro crate" if it already did all its code generation job when compiling "Library crate".
Right?
Wrong!
Hygiene data and spans (https://github.com/rust-lang/rust/issues/68686, https://github.com/rust-lang/rust/pull/68941) from "Macro crate" still may need to be decoded from "Executable crate".
So we'll have to load them properly.
Questions:
- How this will affect compile times for larger crate trees in practice? How to measure it?
Hygiene/span encoding/decoding will necessarily slow down compilation because right now we just don't do some work that we should do, but this introduces a whole new way to slow down things. E.g. loading metadata for `syn` (and its dependencies) when compiling your executable if one of its library dependencies uses it.
- We are currently detecting whether a crate reexports macros from "Macro crate" or not, could we similarly detect whether a crate "reexports spans" and keep it unloaded if it doesn't?
Or at least "reexports important spans" affecting hygiene, we can probably lose spans that only affect diagnostics.
* Reorder flags to group similar ones together
* Make some flags more granular
* Compute `HAS_FREE_LOCAL_NAMES` from the other flags
* Remove `HAS_TY_CLOSURE`
* Add some more doc comments
* Add a new method `has_infer_types_or_consts` that's used instead most
of the time, since there's generally no reason to only consider types.
* Remove use of `has_closure_types`, because closures are no longer
implicitly linked to the `InferCtxt`.
Clarify explanation of Vec<T> 'fn resize'
1. Clarified on what should implement `Clone` trait.
2. Minor grammar fix:
to be able clone => to be able **to** clone
Use assert_ne in hash tests
The hash tests were written before the assert_ne macro was added to the standard library. The assert_ne macro provides better output in case of a failure.
Rollup of 7 pull requests
Successful merges:
- #69397 (bootstrap: Remove commit hash from LLVM version suffix to avoid rebuilds)
- #69549 (Improve MinGW detection when cross compiling )
- #69562 (Don't `bug` when taking discriminant of generator during dataflow)
- #69579 (parser: Remove `Parser::prev_span`)
- #69580 (use .copied() instead of .map(|x| *x) on iterators)
- #69583 (Do not ICE on invalid type node after parse recovery)
- #69605 (Use `opt_def_id()` over `def_id()`)
Failed merges:
r? @ghost
Don't `bug` when taking discriminant of generator during dataflow
The proper fix for rust-lang/rust-clippy#5239. `Rvalue::Discriminant` is used on generators as well as `enum`s. This didn't cause a test failure in `rustc` since we don't need to do any dataflow passes until after the generator transform that adds the `Rvalue::Discriminant`.
This required a small refactoring. `diff -w` is beneficial.
r? @oli-obk
cc @JohnTitor
Improve MinGW detection when cross compiling
Official mingw-w64 builds, MSYS2 and LLVM MinGW provide both `gcc.exe` and `$ARCH-w64-mingw32-gcc.exe` so they should not regress but I included CI changes to verify it though `@bors try` (I don't have permission).
This change will come handy when cross compiling from Linux or Cygwin since they use `gcc` as native compiler and `$ARCH-w64-mingw32-gcc.exe` for MinGW. This means users will no longer have to override the linker.
bootstrap: Remove commit hash from LLVM version suffix to avoid rebuilds
The custom LLVM version suffix was introduced to avoid unintentional
library names conflicts. By default it included the LLVM submodule
commit hash. Changing the version suffix requires the complete LLVM
rebuild, and since then every change to the submodules required it as
well.
Remove the commit hash from version suffix to avoid complete rebuilds,
while leaving the `rust` string, the release number and release channel
to disambiguate the library name.
Context: version suffix was introduced by #59173 as solution to #59034.
Resolves#68715.
Use new dataflow framework for generators
#65672 introduced a new dataflow framework that can handle arbitrarily complex transfer functions as well as ones expressed as a series of gen/kill operations. This PR ports the analyses used to implement generators to the new framework so that we can remove the old one. See #68241 for a prior example of this. The new framework has some superficial API changes, but this shouldn't alter the generator passes in any way.
r? @tmandry
Skip `Drop` terminators for enum variants without drop glue
Split out from #68528.
When doing drop elaboration for an `enum` that may or may not be moved out of (an open drop), we check the discriminant of the `enum` to see whether the live variant has any drop flags and then check the drop flags to see whether we need to drop each field. Sometimes, however, the live
variant has no move paths and thus no drop flags. In this case, we still emit a drop terminator
for the entire enum after checking the enum discriminant. This drop shim will check the discriminant of the enum *again* and then drop the fields of the active variant. If the active variant has no drop glue, nothing will be done.
This commit skips emitting the drop terminator during drop elaboration when the "otherwise" variants, those without move paths, have no drop glue. A common example of this scenario is when an `Option` is moved from, since `Option::None` never needs drop glue. Below is a fragment the pre-codegen CFG for `Option::unwrap_or` in which we check the drop flag (`_5`) for `self` (`_1`), before and after the change.
Before:

After:
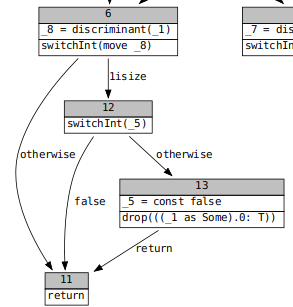
This change doesn't do much on its own, but it is a prerequisite to get the perf gains from #68528.
cc @arielb1
Rename `libsyntax` to `librustc_ast`
This was the last rustc crate that wasn't following the `rustc_*` naming convention.
Follow-up to https://github.com/rust-lang/rust/pull/67763.
Implementes suggeseted changes by Centril.
This checks whether the memory location of the cast remains the same
after atttempting to parse a postfix operator after a cast has been
parsed. If the address is not the same, an illegal postfix operator
was parsed.
Previously the code generated a hash of the pointer, which was overly
complex and inefficent. Casting the pointers and comparing them
is simpler and more effcient.
{kind=link}
{kind=link}