Fixes#73268
When a deref coercion occurs, we may end up with a move error if the
base value has been partially moved out of. However, we do not indicate
anywhere that a deref coercion is occuring, resulting in an error
message with a confusing span.
This PR adds an explicit note to move errors when a deref coercion is
involved. We mention the name of the type that the deref-coercion
resolved to, as well as the `Deref::Target` associated type being used.
BTreeMap: move up reference to map's root from NodeRef
Since the introduction of `NodeRef` years ago, it also contained a mutable reference to the owner of the root node of the tree (somewhat disguised as *const). Its intent is to be used only when the rest of the `NodeRef` is no longer needed. Moving this to where it's actually used, thought me 2 things:
- Some sort of "postponed mutable reference" is required in most places that it is/was used, and that's exactly where we also need to store a reference to the length (number of elements) of the tree, for the same reason. The length reference can be a normal reference, because the tree code does not care about tree length (just length per node).
- It's downright obfuscation in `from_sorted_iter` (transplanted to #75329)
- It's one of the reasons for the scary notice on `reborrow_mut`, the other one being addressed in #73971.
This does repeat the raw pointer code in a few places, but it could be bundled up with the length reference.
r? `@Mark-Simulacrum`
Use intra-doc links in `core::ptr`
Part of #75080.
The only link that I did not change is a link to a function on the
`pointer` primitive because intra-doc links for the `pointer` primitive
don't work yet (see #63351).
---
@rustbot modify labels: A-intra-doc-links T-doc
Add drain_filter method to HashMap and HashSet
Add `HashMap::drain_filter` and `HashSet::drain_filter`, implementing part of rust-lang/rfcs#2140. These new methods are unstable. The tracking issue is #59618.
The added iterators behave the same as `BTreeMap::drain_filter` and `BTreeSet::drain_filter`, except their iteration order is arbitrary. The unit tests are adapted from `alloc::collections::btree`.
This branch rewrites `HashSet` to be a wrapper around `hashbrown::HashSet` rather than `std::collections::HashMap`.
(Both are themselves wrappers around `hashbrown::HashMap`, so the in-memory representation is the same either way.) This lets `std` re-use more iterator code from `hashbrown`. Without this change, we would need to duplicate much more code to implement `HashSet::drain_filter`.
This branch also updates the `hashbrown` crate to version 0.9.0. Aside from changes related to the `DrainFilter` iterators, this version only changes features that are not used in libstd or rustc. And it updates `indexmap` to version 1.6.0, whose only change is compatibility with `hashbrown` 0.9.0.
This avoids overlapping a reference covering the data field,
which may be changed due in concurrent conditions. This fully
fixed the UB mainfested with `new_cyclic`.
BTreeMap mutable iterators should not take any reference to visited nodes during iteration
Fixes#73915, overlapping mutable references during BTreeMap iteration
r? `@RalfJung`
`write` is ambiguous because there's also a macro called `write`.
Also removed unnecessary and potentially confusing link to a function in
its own docs.
The only link that I did not change is a link to a function on the
`pointer` primitive because intra-doc links for the `pointer` primitive
don't work yet (see #63351).
ManuallyDrop's documentation tells the user to use MaybeUninit instead
when handling uninitialized data. However, the main functionality of
ManuallyDrop (drop) was not available directly on MaybeUninit. Adding it
makes it easier to switch from one to the other.
Implement Seek::stream_position() for BufReader
Optimization over `BufReader::seek()` for getting the current position without flushing the internal buffer.
Related to #31100. Based on the code in #70577.
Remove unneeded `#[cfg(not(test))]` from libcore
This fixes rust-analyzer inside these modules (currently it does not analyze them, assuming they're configured out).
Use ops::ControlFlow in rustc_data_structures::graph::iterate
Since I only know about this because you mentioned it,
r? @ecstatic-morse
If we're not supposed to use new `core` things in compiler for a while then feel free to close, but it felt reasonable to merge the two types since they're the same, and it might be convenient for people to use `?` in their traversal code.
(This doesn't do the type parameter swap; NoraCodes has signed up to do that one.)
time.rs: Make spelling of "Darwin" consistent
On line 89 of this file, the OS name is written as "Darwin", but on line 162 it is written in all-caps. Darwin is usually spelt as a standard proper noun, i.e. "Darwin", rather than in all-caps.
This change makes that form consistent in both places.
Indent a note to make folding work nicer
Sublime Text folds code based on indentation. It maybe an unnecessary change, but does it look nicer after that ?
Move various ui const tests to `library`
Move:
- `src\test\ui\consts\const-nonzero.rs` to `library\core`
- `src\test\ui\consts\ascii.rs` to `library\core`
- `src\test\ui\consts\cow-is-borrowed` to `library\alloc`
Part of #76268
r? @matklad
Make `Ipv4Addr` and `Ipv6Addr` const tests unit tests under `library`
These tests are about the standard library, not the compiler itself, thus should live in `library`, see #76268.
Move some Vec UI tests into alloc unit tests
A bit of work towards #76268, makes a number of the Vec UI tests that are simply running code into unit tests. Ensured that they are being run when testing liballoc locally.
Try to improve the documentation of `filter()` and `filter_map()`.
I believe the documentation is currently a little misleading.
For example, in the docs for `filter()`:
> If the closure returns `false`, it will try again, and call the closure on
> the next element, seeing if it passes the test.
This kind of implies that if the closure returns true then we *don't* "try
again" and no further elements are considered. In actuality that's not the
case, every element is tried regardless of what happened with the previous
element.
This change tries to clarify that by removing the uses of "try again"
altogether.
Use Arc::clone and Rc::clone in documentation
This PR replaces uses of `x.clone()` by `Rc::clone(&x)` (or `Arc::clone(&x)`) to better match the documentation for those types.
@rustbot modify labels: T-doc
rename MaybeUninit slice methods
The `first` methods conceptually point to the whole slice, not just its first element, so rename them to be consistent with the raw ptr methods on ref-slices.
Also, do the equivalent of https://github.com/rust-lang/rust/pull/76047 for the slice reference getters, and make them part of https://github.com/rust-lang/rust/issues/63569 (so far they somehow had no tracking issue).
* first_ptr -> slice_as_ptr
* first_ptr_mut -> slice_as_mut_ptr
* slice_get_ref -> slice_assume_init_ref
* slice_get_mut -> slice_assume_init_mut
I believe the documentation is currently a little misleading.
For example, in the docs for `filter()`:
> If the closure returns `false`, it will try again, and call the closure on
> the next element, seeing if it passes the test.
This kind of implies that if the closure returns true then we *don't* "try
again" and no further elements are considered. In actuality that's not the
case, every element is tried regardless of what happened with the previous
element.
This change tries to clarify that by removing the uses of "try again"
altogether.
Enable some of profiler tests on Windows-gnu
CC https://github.com/rust-lang/rust/issues/61266
Because of force-push GitHub didn't let me reopen https://github.com/rust-lang/rust/pull/75184
Because of the GCC miscompilation, generated binaries either segfault or `.profraw` is malformed. Clang works fine but we can't use it on the CI.
However we can still test the IR for the proper instrumentation so let's do it.
BTreeMap: introduce marker::ValMut and reserve Mut for unique access
The mutable BTreeMap iterators (apart from `DrainFilter`) are double-ended, meaning they have to rely on a front and a back handle that each represent a reference into the tree. Reserve a type category `marker::ValMut` for them, so that we guarantee that they cannot reach operations on handles with borrow type `marker::Mut`and that these operations can assume unique access to the tree.
Including #75195, benchmarks report no genuine change:
```
benchcmp old new --threshold 5
name old ns/iter new ns/iter diff ns/iter diff % speedup
btree::map::iter_100 3,333 3,023 -310 -9.30% x 1.10
btree::map::range_unbounded_vs_iter 36,624 31,569 -5,055 -13.80% x 1.16
```
r? @Mark-Simulacrum
Respect `-Z proc-macro-backtrace` flag for panics inside libproc_macro
Fixes#76270
Previously, any panic occuring during a call to a libproc_macro method
(e.g. calling `Ident::new` with an invalid identifier) would always
cause an ICE message to be printed.
Move:
- `src\test\ui\consts\const-nonzero.rs` to `library\core`
- `src\test\ui\consts\ascii.rs` to `library\core`
- `src\test\ui\consts\cow-is-borrowed` to `library\alloc`
Part of #76268
specialize some collection and iterator operations to run in-place
This is a rebase and update of #66383 which was closed due inactivity.
Recent rustc changes made the compile time regressions disappear, at least for webrender-wrench. Running a stage2 compile and the rustc-perf suite takes hours on the hardware I have at the moment, so I can't do much more than that.
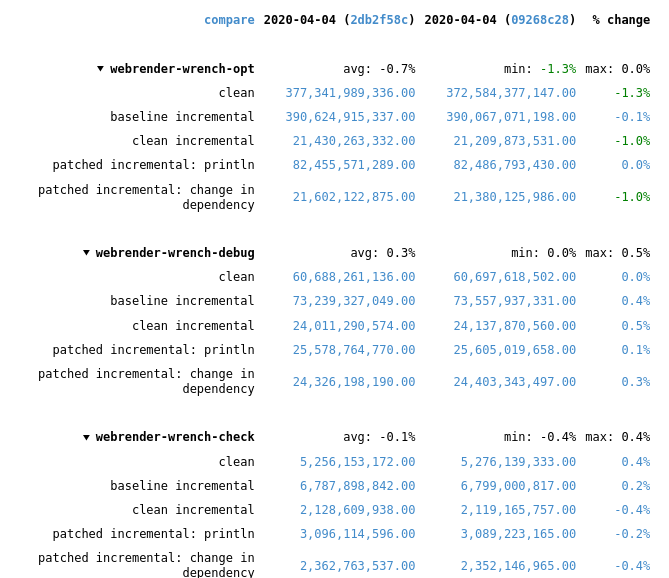
In the best case of the `vec::bench_in_place_recycle` synthetic microbenchmark these optimizations can provide a 15x speedup over the regular implementation which allocates a new vec for every benchmark iteration. [Benchmark results](https://gist.github.com/the8472/6d999b2d08a2bedf3b93f12112f96e2f). In real code the speedups are tiny, but it also depends on the allocator used, a system allocator that uses a process-wide mutex will benefit more than one with thread-local pools.
## What was changed
* `SpecExtend` which covered `from_iter` and `extend` specializations was split into separate traits
* `extend` and `from_iter` now reuse the `append_elements` if passed iterators are from slices.
* A preexisting `vec.into_iter().collect::<Vec<_>>()` optimization that passed through the original vec has been generalized further to also cover cases where the original has been partially drained.
* A chain of *Vec<T> / BinaryHeap<T> / Box<[T]>* `IntoIter`s through various iterator adapters collected into *Vec<U>* and *BinaryHeap<U>* will be performed in place as long as `T` and `U` have the same alignment and size and aren't ZSTs.
* To enable above specialization the unsafe, unstable `SourceIter` and `InPlaceIterable` traits have been added. The first allows reaching through the iterator pipeline to grab a pointer to the source memory. The latter is a marker that promises that the read pointer will advance as fast or faster than the write pointer and thus in-place operation is possible in the first place.
* `vec::IntoIter` implements `TrustedRandomAccess` for `T: Copy` to allow in-place collection when there is a `Zip` adapter in the iterator. TRA had to be made an unstable public trait to support this.
## In-place collectible adapters
* `Map`
* `MapWhile`
* `Filter`
* `FilterMap`
* `Fuse`
* `Skip`
* `SkipWhile`
* `Take`
* `TakeWhile`
* `Enumerate`
* `Zip` (left hand side only, `Copy` types only)
* `Peek`
* `Scan`
* `Inspect`
## Concerns
`vec.into_iter().filter(|_| false).collect()` will no longer return a vec with 0 capacity, instead it will return its original allocation. This avoids the cost of doing any allocation or deallocation but could lead to large allocations living longer than expected.
If that's not acceptable some resizing policy at the end of the attempted in-place collect would be necessary, which in the worst case could result in one more memcopy than the non-specialized case.
## Possible followup work
* split liballoc/vec.rs to remove `ignore-tidy-filelength`
* try to get trivial chains such as `vec.into_iter().skip(1).collect::<Vec<)>>()` to compile to a `memmove` (currently compiles to a pile of SIMD, see #69187 )
* improve up the traits so they can be reused by other crates, e.g. itertools. I think currently they're only good enough for internal use
* allow iterators sourced from a `HashSet` to be in-place collected into a `Vec`
The InPlaceIterable debug assert checks that the write pointer
did not advance beyond the read pointer. But TrustedRandomAccess
never advances the read pointer, thus triggering the assert.
Skip the assert if the source pointer did not change during iteration.
rustdoc: do not use plain summary for trait impls
Fixes#38386.
Fixes#48332.
Fixes#49430.
Fixes#62741.
Fixes#73474.
Unfortunately this is not quite ready to go because the newly-working links trigger a bunch of linkcheck failures. The failures are tough to fix because the links are resolved relative to the implementor, which could be anywhere in the module hierarchy.
(In the current docs, these links end up rendering as uninterpreted markdown syntax, so I don't think these failures are any worse than the status quo. It might be acceptable to just add them to the linkchecker whitelist.)
Ideally this could be fixed with intra-doc links ~~but it isn't working for me: I am currently investigating if it's possible to solve it this way.~~ Opened #73829.
EDIT: This is now ready!
The optimization meant that every extend code path had to emit llvm
IR for from_iter and extend spec_extend, which likely impacts
compile times while only improving a few edge-cases
{kind=link}