Instead of finding the next free disambiguator by incrementing it until
you find a place, store the next available disambiguator in an hash-map.
This avoids O(n^2) performance when lots of items have the same
un-disambiguated `DefPathData` - e.g. all `use` items have
`DefPathData::Misc`.
We already had a cache for file contents, but we read the source-file
before testing the cache, causing obvious slowness, so this just avoids
loading the source-file when the cache already has the contents.
rustbuild: Update cross-compilers for FreeBSD
When working through bugs for the LLVM 5.0 upgrade it looks like the FreeBSD
cross compilers we're currently using are unable to build LLVM, failing with
references to the function `std::to_string` claiming it doesn't exist. I don't
actually know what this function is, but assuming that it was added in a more
recent version of a C++ standard I've updated the gcc versions for the
toolchains we're using. This made the error go away!
rustbuild: Tweak how we cross-compile LLVM
In preparation for upgrading to LLVM 5.0 it looks like we need to tweak how we
cross compile LLVM slightly. It's using `CMAKE_SYSTEM_NAME` to infer whether to
build libFuzzer which only works on some platforms, and then once we configure
that it needs to apparently reach into the host build area to try to compile
`llvm-config` as well. Once these are both configured, though, it looks like we
can successfully cross-compile LLVM.
Support homogeneous aggregates for hard-float ARM
Hard-float ARM targets use the AAPCS-VFP ABI, which passes and returns
homogeneous float/vector aggregates in the VFP registers.
Fixes#43329.
r? @eddyb
When working through bugs for the LLVM 5.0 upgrade it looks like the FreeBSD
cross compilers we're currently using are unable to build LLVM, failing with
references to the function `std::to_string` claiming it doesn't exist. I don't
actually know what this function is, but assuming that it was added in a more
recent version of a C++ standard I've updated the gcc versions for the
toolchains we're using. This made the error go away!
In preparation for upgrading to LLVM 5.0 it looks like we need to tweak how we
cross compile LLVM slightly. It's using `CMAKE_SYSTEM_NAME` to infer whether to
build libFuzzer which only works on some platforms, and then once we configure
that it needs to apparently reach into the host build area to try to compile
`llvm-config` as well. Once these are both configured, though, it looks like we
can successfully cross-compile LLVM.
Implement tokenization for some items in proc_macro
This PR is a partial implementation of https://github.com/rust-lang/rust/issues/43081 targeted towards preserving span information in attribute-like procedural macros. Currently all attribute-like macros will lose span information with the input token stream if it's iterated over due to the inability of the compiler to losslessly tokenize an AST node. This PR takes a strategy of saving off a list of tokens in particular AST nodes to return a lossless tokenized version. There's a few limitations with this PR, however, so the old fallback remains in place.
This is then later used by `proc_macro` to generate a new
`proc_macro::TokenTree` which preserves span information. Unfortunately this
isn't a bullet-proof approach as it doesn't handle the case when there's still
other attributes on the item, especially inner attributes.
Despite this the intention here is to solve the primary use case for procedural
attributes, attached to functions as outer attributes, likely bare. In this
situation we should be able to now yield a lossless stream of tokens to preserve
span information.
improve case with both anonymous lifetime parameters #43269
This is a fix to #43269.
Sample output message-
```
error[E0623]: lifetime mismatch
--> $DIR/ex3-both-anon-regions.rs:12:12
|
11 | fn foo(x: &mut Vec<&u8>, y: &u8) {
| --- --- these references must have the same lifetime
12 | x.push(y);
| ^ data from `y` flows into `x` here
error: aborting due to 2 previous errors
```
r? @nikomatsakis
This test currently fails because the tokenization of an AST item during the
expansion of a procedural macro attribute rounds-trips through strings, losing
span information.
This partly resolves the `FIXME` located in `src/libproc_macro/lib.rs` when
interpreting interpolated tokens. All instances of `ast::Item` which have a list
of tokens attached to them now use that list of tokens to losslessly get
converted into a `TokenTree` instead of going through stringification and losing
span information.
cc #43081
This commit adds a new field to the `Item` AST node in libsyntax to optionally
contain the original token stream that the item itself was parsed from. This is
currently `None` everywhere but is intended for use later with procedural
macros.
The function should accept feature strings that old LLVM might not
support.
Simplify the code using the same approach used by
LLVMRustPrintTargetFeatures.
Dummify the function for non 4.0 LLVM and update the tests accordingly.
Provide positional information when visiting ty, substs and closure_substs in MIR
This will enable the region renumbering portion of #43234 (non-lexical lifetimes). @nikomatsakis's current plan [here](https://gist.github.com/nikomatsakis/dfc27b28cd024eb25054b52bb11082f2) shows that we need spans of the original code to create new region variables, e.g. `self.infcx.next_region_var(infer::MiscVariable(span))`. The current visitor impls did not pass positional information (`Location` in some, `Span` and `SourceInfo` for others) for all types. I did not expand this to all visits, just the ones necessary for the above-mentioned plan.
Embed MSVC .natvis files into .pdbs and mangle debuginfo for &str, *T, and [T].
No idea if these changes are reasonable - please feel free to suggest changes/rewrites. And these are some of my first real commits to any rust codebase - *don't* be gentle, and nitpick away, I need to learn! ;)
### Overview
Embedding `.natvis` files into `.pdb`s allows MSVC (and potentially other debuggers) to automatically pick up the visualizers without having to do any additional configuration (other than to perhaps add the relevant .pdb paths to symbol search paths.)
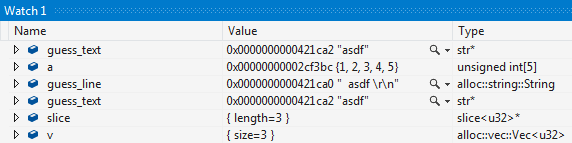
The native debug engine for MSVC parses the type names, making various C++ish assumptions about what they mean and adding various limitations to valid type names. `&str` cannot be matched against a visualizer, but if we emit `str&` instead, it'll be recognized as a reference to a `str`, solving the problem. `[T]` is similarly problematic, but emitting `slice<T>` instead works fine as it looks like a template. I've been unable to get e.g. `slice<u32>&` to match visualizers in VS2015u3, so I've gone with `str*` and `slice<u32>*` instead.
### Possible Issues
* I'm not sure if `slice<T>` is a great mangling for `[T]` or if I should worry about name collisions.
* I'm not sure if `linker.rs` is the right place to be enumerating natvis files.
* I'm not sure if these type name mangling changes should actually be MSVC specific. I recall seeing gdb visualizer tests that might be broken if made more general? I'm hesitant to mess with them without a gdb install. But perhaps I'm just wracking up technical debt.
Should I try `pacman -S mingw-w64-x86_64-gdb` and to make things consistent?
* I haven't touched `const` / `mut` yet, and I'm worried MSVC might trip up on `mut` or their placement.
* I may like terse oneliners too much.
* I don't know if there's broader implications for messing with debug type names here.
* I may have been mistaken about bellow test failures being ignorable / unrelated to this changelist.
### Test Failures on `x86_64-pc-windows-gnu`
```
---- [debuginfo-gdb] debuginfo-gdb\associated-types.rs stdout ----
thread '[debuginfo-gdb] debuginfo-gdb\associated-types.rs' panicked at 'gdb not available but debuginfo gdb debuginfo test requested', src\tools\compiletest\src\runtest.rs:48:16
note: Run with `RUST_BACKTRACE=1` for a backtrace.
[...identical panic causes omitted...]
---- [debuginfo-gdb] debuginfo-gdb\vec.rs stdout ----
thread '[debuginfo-gdb] debuginfo-gdb\vec.rs' panicked at 'gdb not available but debuginfo gdb debuginfo test requested', src\tools\compiletest\src\runtest.rs:48:16
```
### Relevant Issues
* https://github.com/rust-lang/rust/issues/40460 Metaissue for Visual Studio debugging Rust
* https://github.com/rust-lang/rust/issues/36503 Investigate natvis for improved msvc debugging
* https://github.com/PistonDevelopers/VisualRust/issues/160 Debug visualization of Rust data structures
### Pretty Pictures

Add precondition to `Layout` that the `align` fit in a u32.
Add precondition to `Layout` that the `align` not exceed 2^31.
This precondition takes the form of a behavorial change in `Layout::from_size_align` (so it returns `None` if the input `align` is too large) and a new requirement for safe usage of `Layout::from_size_align_unchecked`.
Fix#30170.
syntax: Simplify parsing of paths
Discern between `Path` and `Path<>` in AST (but not in HIR).
Give span to angle bracketed generic arguments (`::<'a, T>` in `path::segment::<'a, T>`).
This is a refactoring in preparation for https://internals.rust-lang.org/t/macro-path-uses-novel-syntax/5561/3, but it doesn't add anything to the grammar yet.
r? @jseyfried
Compile rustdoc on-demand
Fixes#43284, fixes#38318, and fixes#39505.
Doesn't directly help with https://github.com/rust-lang/rust/issues/42686, since we need to rebuild just as much. In fact, this hurts it, since `./x.py doc --stage 0` will now fail. I'm not sure if it did before, but with these changes it runs into the problem where we attempt to use artifacts from bootstrap rustc with a non-bootstrap rustdoc, running into version conflicts. I believe this is solvable, but leaving for a future PR.
This means that rustdoc will no longer be compiled when compiling rustc, by default. However, it is still built from `./x.py build` (for hosts, but not targets, since we don't produce compiler toolchains for them) and will be built for doc tests and crate tests.
After this, the recommended workflow if you want a rustdoc is: `./x.py build --stage 1 src/tools/rustdoc` which will give you a working rustdoc in `build/triple/stage1/bin/rustdoc`. Note that you can add `src/libstd` onto the command to compile libstd as well so that the rustdoc can easily compile crates in the wild. `./x.py doc --stage 1 src/libstd` will document `libstd` with a freshly built rustdoc (if necessary), and will not rebuild rustc on modifications to rustdoc.
r? @alexcrichton
Copyright/license headers
(As discussed with @aturon and @est31. CC @rust-lang/core.)
Currently, rust-lang/rust includes notices that say things like
```
The Rust Project is copyright 2010, The Rust Project
Developers.
```
or
```
Copyright (c) 2010 The Rust Project Developers
```
or
```
// Copyright 2017 The Rust Project Developers. See the COPYRIGHT
// file at the top-level directory of this distribution and at
// http://rust-lang.org/COPYRIGHT.
```
These notices aren't accurate. "Copyright YYYY Some Name" has a specific legal meaning, and "The Rust Project Developers" isn't a legal entity. In practice, the actual legal structure is that all Rust contributors retain their copyrights when contributing to Rust, and just license them under MIT/Apache-2.0. Our legal notices should reflect that.
This came up because of RFC 2044, which proposed fixing this for the RFC repository. That effort started out by copying the rust-lang/rust notices, propagating this issue.
Based on discussion with @aturon, the two of us propose the following:
- Delete the per-file notices entirely, for any files licensed under the standard terms. (Keep notices for anything that's *not* MIT/Apache-2.0.)
- An alternative to that would be to just delete the first paragraph of the standard notice, and keep the second paragraph that points to the MIT and Apache 2.0 licenses.
- Delete the first paragraph of LICENSE-MIT (the inaccurate pseudo-copyright line), leaving only the text of the MIT license.
- Edit the COPYRIGHT file to more accurately describe the situation (changing the pseudo-copyright line immediately under "longer version", and editing the text that starts with "additional copyright may be ...", to just always state that copyrights are retained by the Rust contributors, and licensed under MIT/Apache-2.0 (with the exceptions to that explicitly noted in that file).
If @rust-lang/core is fine with this proposal, I'd be happy to provide a pull request with the proposed fixes.
Extended error message for mut borrow conflicts in loops
RFC issue: https://github.com/rust-lang/rfcs/issues/2080
The error message for multiple mutable borrows on the same value over loop iterations now makes it clear that the conflict comes from the borrow outlasting the loop. The wording of the error is based on the special case of the moved-value error for a value moved in a loop. Following the example of that error, the code remains the same for the special case.
This is mainly because I felt the current message is confusing in the loop case : https://github.com/rust-lang/rust/issues/43437. It's not clear that the two conflicting borrows are in different iterations of the loop, and instead it just looks like the compiler has an issue with a single line.
{kind=link}
{kind=link}
{kind=link}