specialize some collection and iterator operations to run in-place
This is a rebase and update of #66383 which was closed due inactivity.
Recent rustc changes made the compile time regressions disappear, at least for webrender-wrench. Running a stage2 compile and the rustc-perf suite takes hours on the hardware I have at the moment, so I can't do much more than that.
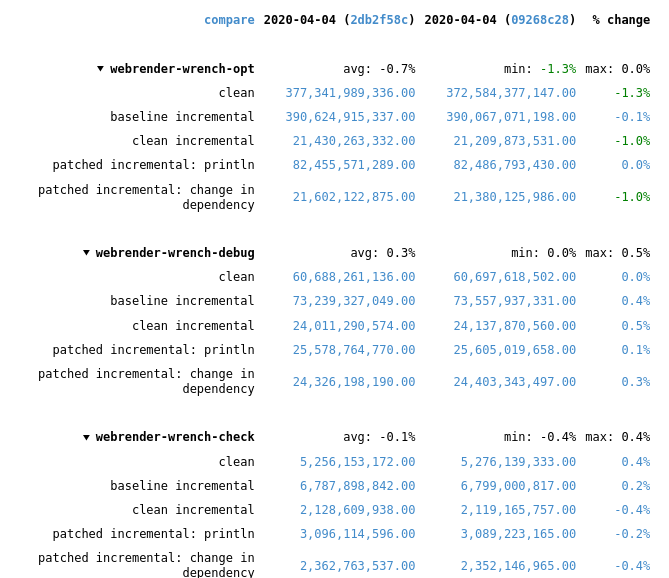
In the best case of the `vec::bench_in_place_recycle` synthetic microbenchmark these optimizations can provide a 15x speedup over the regular implementation which allocates a new vec for every benchmark iteration. [Benchmark results](https://gist.github.com/the8472/6d999b2d08a2bedf3b93f12112f96e2f). In real code the speedups are tiny, but it also depends on the allocator used, a system allocator that uses a process-wide mutex will benefit more than one with thread-local pools.
## What was changed
* `SpecExtend` which covered `from_iter` and `extend` specializations was split into separate traits
* `extend` and `from_iter` now reuse the `append_elements` if passed iterators are from slices.
* A preexisting `vec.into_iter().collect::<Vec<_>>()` optimization that passed through the original vec has been generalized further to also cover cases where the original has been partially drained.
* A chain of *Vec<T> / BinaryHeap<T> / Box<[T]>* `IntoIter`s through various iterator adapters collected into *Vec<U>* and *BinaryHeap<U>* will be performed in place as long as `T` and `U` have the same alignment and size and aren't ZSTs.
* To enable above specialization the unsafe, unstable `SourceIter` and `InPlaceIterable` traits have been added. The first allows reaching through the iterator pipeline to grab a pointer to the source memory. The latter is a marker that promises that the read pointer will advance as fast or faster than the write pointer and thus in-place operation is possible in the first place.
* `vec::IntoIter` implements `TrustedRandomAccess` for `T: Copy` to allow in-place collection when there is a `Zip` adapter in the iterator. TRA had to be made an unstable public trait to support this.
## In-place collectible adapters
* `Map`
* `MapWhile`
* `Filter`
* `FilterMap`
* `Fuse`
* `Skip`
* `SkipWhile`
* `Take`
* `TakeWhile`
* `Enumerate`
* `Zip` (left hand side only, `Copy` types only)
* `Peek`
* `Scan`
* `Inspect`
## Concerns
`vec.into_iter().filter(|_| false).collect()` will no longer return a vec with 0 capacity, instead it will return its original allocation. This avoids the cost of doing any allocation or deallocation but could lead to large allocations living longer than expected.
If that's not acceptable some resizing policy at the end of the attempted in-place collect would be necessary, which in the worst case could result in one more memcopy than the non-specialized case.
## Possible followup work
* split liballoc/vec.rs to remove `ignore-tidy-filelength`
* try to get trivial chains such as `vec.into_iter().skip(1).collect::<Vec<)>>()` to compile to a `memmove` (currently compiles to a pile of SIMD, see #69187 )
* improve up the traits so they can be reused by other crates, e.g. itertools. I think currently they're only good enough for internal use
* allow iterators sourced from a `HashSet` to be in-place collected into a `Vec`
rustdoc: do not use plain summary for trait impls
Fixes#38386.
Fixes#48332.
Fixes#49430.
Fixes#62741.
Fixes#73474.
Unfortunately this is not quite ready to go because the newly-working links trigger a bunch of linkcheck failures. The failures are tough to fix because the links are resolved relative to the implementor, which could be anywhere in the module hierarchy.
(In the current docs, these links end up rendering as uninterpreted markdown syntax, so I don't think these failures are any worse than the status quo. It might be acceptable to just add them to the linkchecker whitelist.)
Ideally this could be fixed with intra-doc links ~~but it isn't working for me: I am currently investigating if it's possible to solve it this way.~~ Opened #73829.
EDIT: This is now ready!
Convert many files to intra-doc links
Helps with https://github.com/rust-lang/rust/issues/75080
r? @poliorcetics
I recommend reviewing one commit at a time, but the diff is small enough you can do it all at once if you like :)
Move to intra-doc links for library/core/src/iter/traits/iterator.rs
Helps with #75080.
@jyn514 We're almost finished with this issue. Thanks for mentoring. If you have other topics to work on just let me know, I will be around in Discord.
@rustbot modify labels: T-doc, A-intra-doc-links
Known issues:
* Link from `core` to `std` (#74481):
[`OsStr`]
[`String`]
[`VecDeque<T>`]
Rename and expose LoopState as ControlFlow
Basic PR for #75744. Addresses everything there except for documentation; lots of examples are probably a good idea.
Add `[T; N]::as_[mut_]slice`
Part of me trying to populate arrays with a couple of basic useful methods, like slices already have. The ability to add methods to arrays were added in #75212. Tracking issue: #76118
This adds:
```rust
impl<T, const N: usize> [T; N] {
pub fn as_slice(&self) -> &[T];
pub fn as_mut_slice(&mut self) -> &mut [T];
}
```
These methods are like the ones on `std::array::FixedSizeArray` and in the crate `arraytools`.
- Use intra-doc links for `std::io` in `std::fs`
- Use intra-doc links for File::read in unix/ext/fs.rs
- Remove explicit intra-doc links for `true` in `net/addr.rs`
- Use intra-doc links in alloc/src/sync.rs
- Use intra-doc links in src/ascii.rs
- Switch to intra-doc links in alloc/rc.rs
- Use intra-doc links in core/pin.rs
- Use intra-doc links in std/prelude
- Use shorter links in `std/fs.rs`
`io` is already in scope.
flt2dec: properly handle uninitialized memory
The float-to-str code currently uses uninitialized memory incorrectly (see https://github.com/rust-lang/rust/issues/76092). This PR fixes that.
Specifically, that code used `&mut [T]` as "out references", but it would be incorrect for the caller to actually pass uninitialized memory. So the PR changes this to `&mut [MaybeUninit<T>]`, and then functions return a `&[T]` to the part of the buffer that they initialized (some functions already did that, indirectly via `&Formatted`, others were adjusted to return that buffer instead of just the initialized length).
What I particularly like about this is that it moves `unsafe` to the right place: previously, the outermost caller had to use `unsafe` to assert that things are initialized; now it is the functions that do the actual initializing which have the corresponding `unsafe` block when they call `MaybeUninit::slice_get_ref` (renamed in https://github.com/rust-lang/rust/pull/76217 to `slice_assume_init_ref`).
Reviewers please be aware that I have no idea how any of this code actually works. My changes were purely mechanical and type-driven. The test suite passes so I guess I didn't screw up badly...
Cc @sfackler this is somewhat related to your RFC, and possibly some of this code could benefit from (a generalized version of) the API you describe there. But for now I think what I did is "good enough".
Fixes https://github.com/rust-lang/rust/issues/76092.
Move to intra-doc links for library/core/src/panic.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Link from `core` to `std` (#74481):
[`set_hook`]
[`String`]
Add more examples to lexicographic cmp on Iterators.
Given two arrays of T1 and T2, the most important rule of lexicographical comparison is that two arrays
of equal length will be compared until the first difference occured.
The examples provided only focuses on the second rule that says that the
shorter array will be filled with some T2 that is less than every T1.
Which is only possible because of the first rule.
rename get_{ref, mut} to assume_init_{ref,mut} in Maybeuninit
References #63568
Rework with comments addressed from #66174
Have replaced most of the occurrences I've found, hopefully didn't miss out anything
r? @RalfJung
(thanks @danielhenrymantilla for the initial work on this)
Get rid of bounds check in slice::chunks_exact() and related function…
…s during construction
LLVM can't figure out in
let rem = self.len() % chunk_size;
let len = self.len() - rem;
let (fst, snd) = self.split_at(len);
and
let rem = self.len() % chunk_size;
let (fst, snd) = self.split_at(rem);
that the index passed to split_at() is smaller than the slice length and
adds a bounds check plus panic for it.
Apart from removing the overhead of the bounds check this also allows
LLVM to optimize code around the ChunksExact iterator better.
{kind=link}